Home
Introduction
OrderFlow is an enterprise-strength order processing and warehouse management system (WMS) with a wealth of configuration options and implementation possibilities.
This document provides a high-level overview of the OrderFlow system and the key business functions it supports.
The intended audience of this document is:
- business leaders who are considering OrderFlow as a solution to the needs of their organisation
- potential users and administrators of the OrderFlow system
The OrderFlow System
OrderFlow is built specifically around the needs of eCommerce fulfilment. It has been designed to help retailers and fulfilment specialists to run their operations with ease, efficiency and control, while providing the optimal level of visibility of these operations.
The diagram below illustrates where OrderFlow is placed in a typical eCommerce operation.
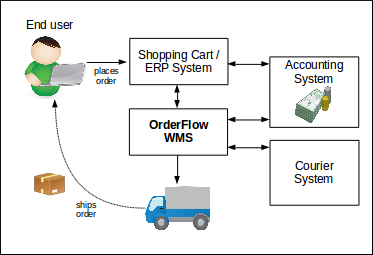
We are all familiar with the process of buying goods online. Through a web-based store, we place orders for products selected from a catalogue, enter our payment details, then click on the 'Buy' button. All this takes place via a Shopping Cart web application.
For small stores taking only a handful of orders, the process of despatching the orders can be done manually. However, for online retailers taking hundreds or thousands of orders per day, this is not an option. For large operations, a dedicated order processing and warehouse management system is essential if this function is to be performed effectively.
OrderFlow manages all the processes that ensure the ordered items are despatched to customers as quickly and efficiently as possible.
Some of the key functions include:
- receiving deliveries of stock into the warehouse
- managing the putaway of stock into storage locations
- directing the processes that optimise the storage of stock in the warehouse
- identifying the stock that can be used to fulfil specific orders, and directing strategies to pick stock efficiently and accurately
- providing facilities for label generation and packing of shipments
- interacting with third party courier systems to retrieve labels and other documentation, and notifying these systems when shipments are despatched from the warehouse
- managing the return of stock items to the warehouse
In addition, there are many other processes that OrderFlow supports which are critical to the operations of specific customer environments.
Each of these processes may involve complex interactions within OrderFlow or with third party systems. Wherever required, OrderFlow provides the user interfaces necessary for warehouse staff, as well as the generation and printing of the appropriate paperwork and reports.
In fulfilling these functions, OrderFlow typically needs to integrate with other external systems. In addition to the Shopping Cart, it often integrates with Enterprise Resource Planning (ERP) systems such as SAP, or accounting systems such as Sage 200. In a typical installation it will also integrate with the software of several couriers, or with a dedicated Courier Management system such as MetaPack.
Desktop Interface
The desktop interface to the OrderFlow system consists of a number of tabs, each of which performs functions in distinct areas of the application. This section provides an overview of the functionality provided within each of the tabs.
Despatch
The Despatch tab is concerned primarily with Order Processing activities.
Screens to search for orders received, shipments to be despatched, and their corresponding order lines are found here. In addition, there are screens for controlling batching, picking, packing and other courier-related operations.
See the Order Processing section for more details.
Inventory
OrderFlow stock control tracks the quantity of every product SKU (Stock Keeping Unit) by location. The movement of every item within the warehouse is tracked. This capability is visible primarily through the Inventory tab.
This tab provides the means to search, view and administer definitions for products and locations. It shows the current stock position as well as historical changes.
It also allows for changes to be made directly to the stock position, via stock moves or stock adjustments.
See the Warehouse Management section for more details.
Warehouse
The Warehouse tab provides access to the warehouse management-related processes on the system. These include the processes for receiving incoming goods through deliveries, which can themselves be associated with purchase orders and advanced shipping notes.
Operations to direct stock movements in the warehouse are accessible here in the form of stock move tasks, as is the processing of stock returns into the warehouse.
See the Warehouse Management section for more details.
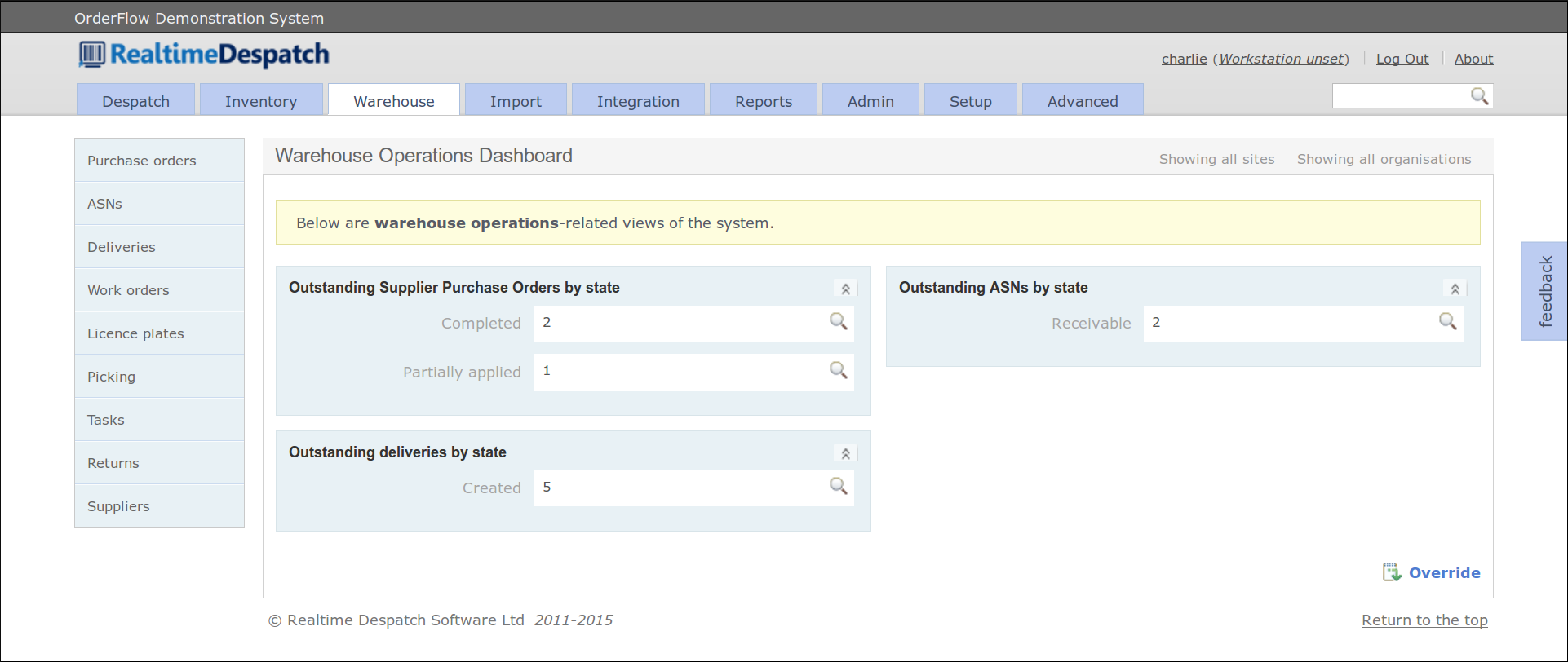
Import
OrderFlow can only perform useful functions once it has been populated with the specific details of the warehouse or warehouses it controls. This includes products, locations, users and orders.
The data can be entered manually when the system is first configured but it usually uploaded in bulk through spreadsheet files or a remote interface. In both cases, the Import tab is used.
This tab provides access to historical records of imported items, and any errors that may have occurred during import. This includes data imported using files (CSV, Excel, XML) as well as directly through the OrderFlow web interface.
See the Import section for more details.
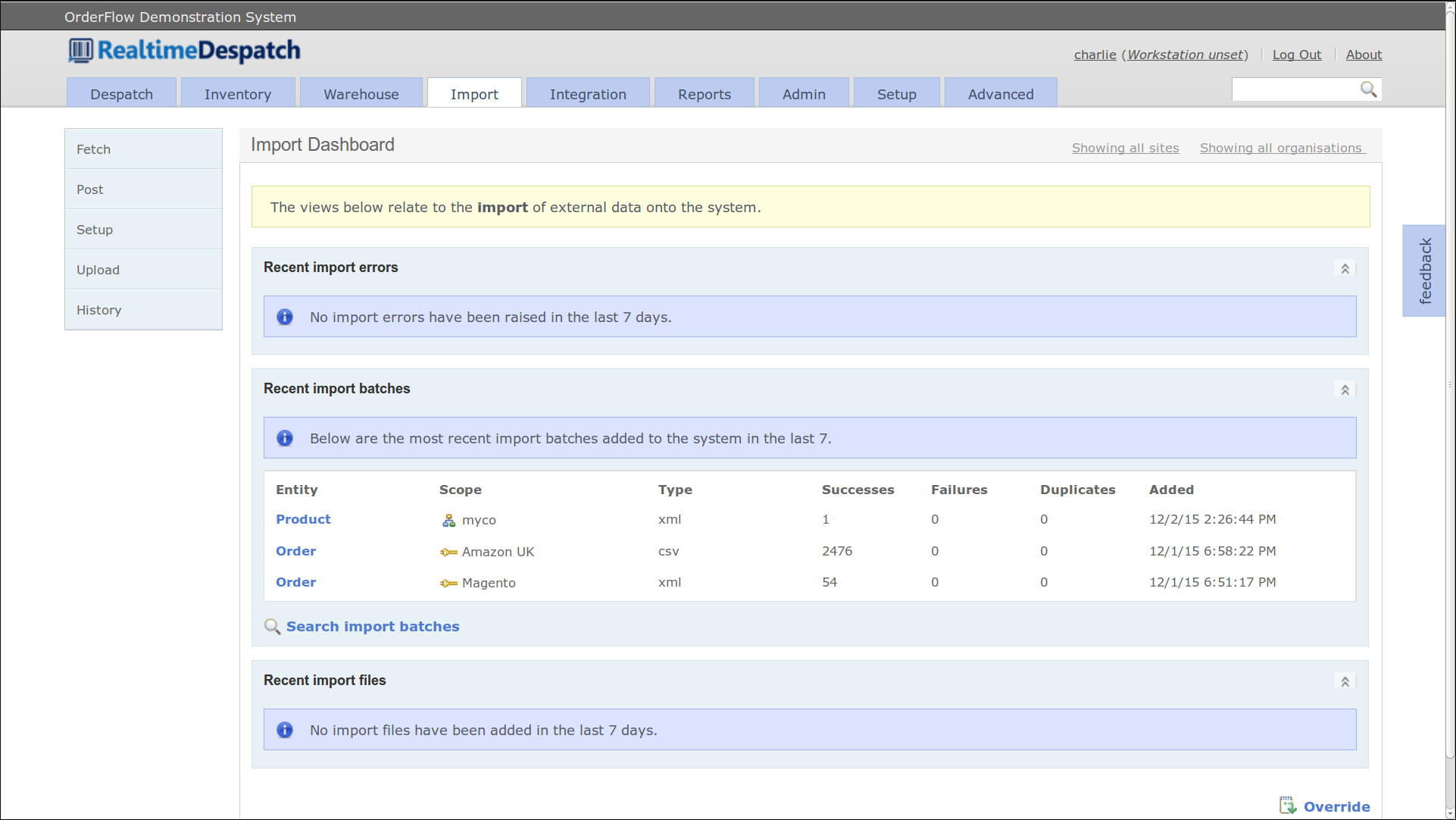
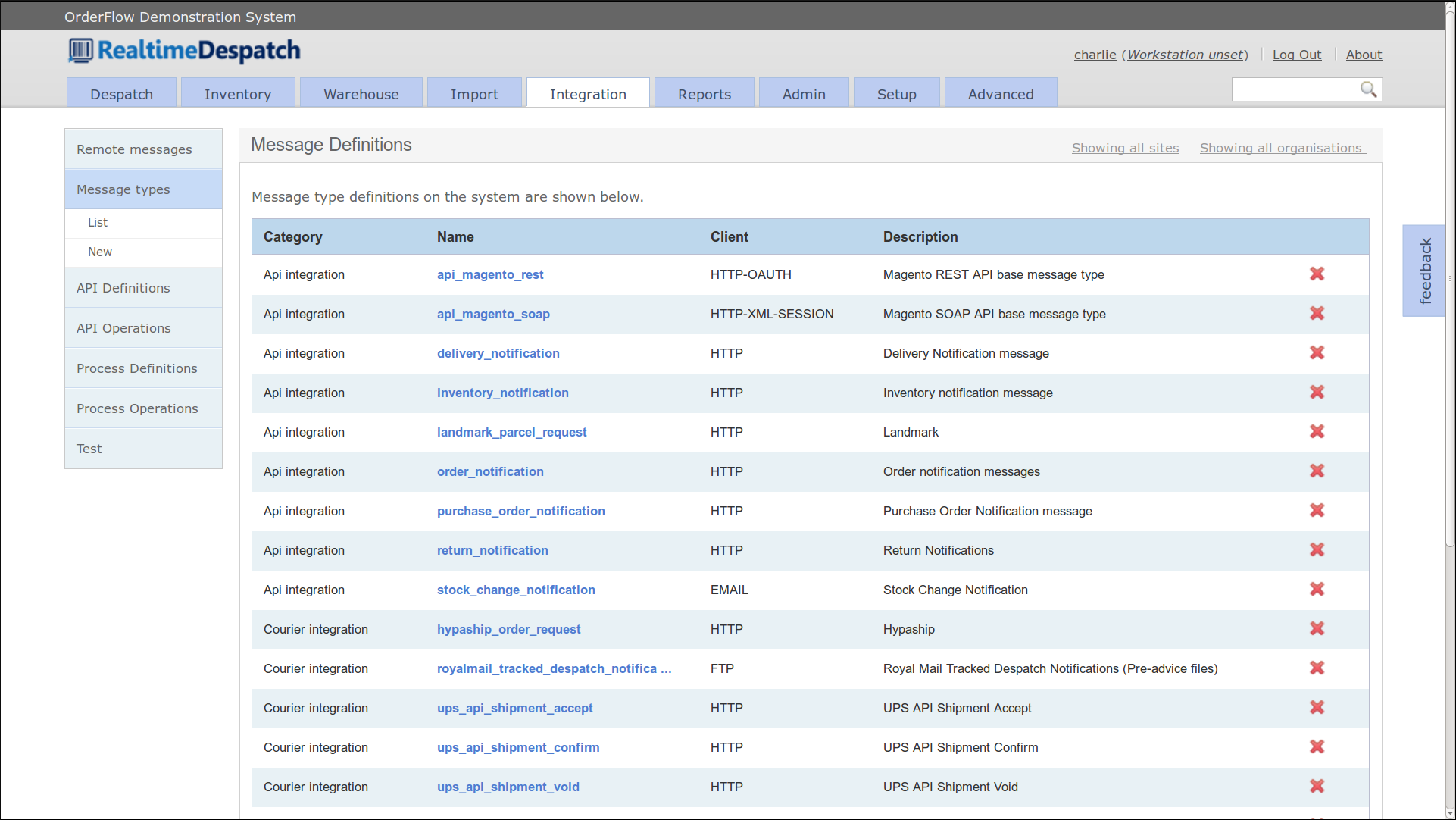
Integration
OrderFlow integrates with many third party applications. The most important of these are eCommerce systems (e.g. Shopping Carts), as these systems are the source of orders fulfilled by OrderFlow.
The Integration tab supports integration with third party systems. See the Integration section for more details.
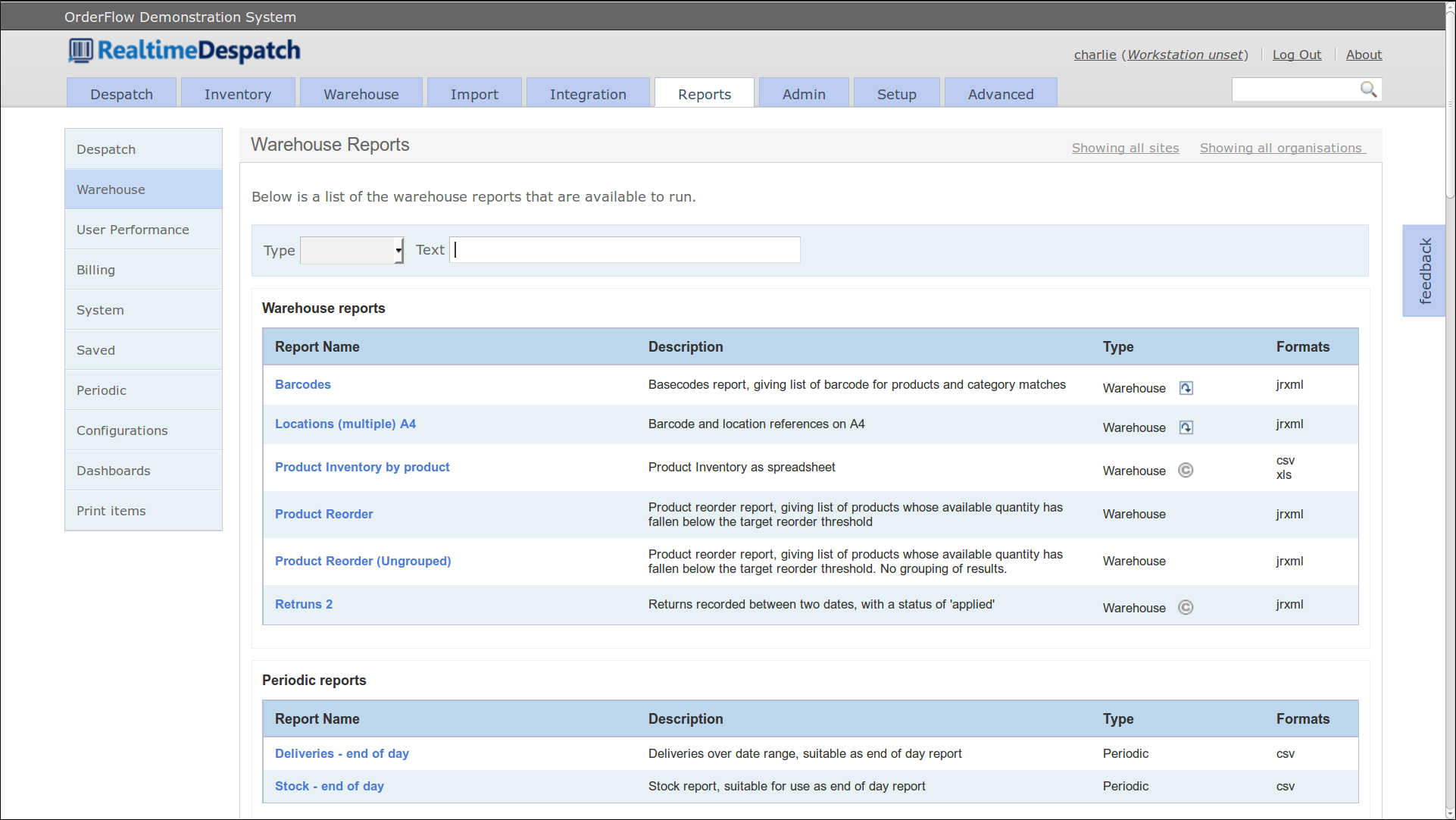
Reports
Reporting is hugely important in OrderFlow. The same reporting framework is used in areas as diverse as the production of customer paperwork (despatch notes and labels), management reports and the dashboards that are part of the user interface. Many of the system processes (such as stock move tasks) are driven by reports.
The Reports module includes the user interface for running built-in reports, as well as for creating new reports, automated reports and dashboards.
See the Reports section for more details.
Admin
The Admin tab provides access to functionality that is not necessarily used by most operational staff, but is still important to the day to day running of the system. User access and permissions, logging, error and performance monitoring are all considered administration functions.
See the Admin section for more details.
Setup
The Setup tab deals with functionality that requires technical knowledge beyond the level of most users. It is normally used when new functionality is released, for example when a new courier is being introduced into the system.
See the Setup section for more details.
Advanced
The Advanced tab deals with functionality that requires technical knowledge beyond the level of most users. Many of the scripting and field mapping options are in this tab, as are configurations for complex areas of the system such as stock move tasks.
See the Advanced section for more details.
Handheld Interface
The Handheld interface to OrderFlow is designed to run on small-screened handheld terminals built specifically for the heavy demands of a warehouse. Almost all of OrderFlow's warehouse management and picking-related functionality is handheld-enabled, although businesses can also choose to use paper-based processing.
The Handheld interface can be accessed from OrderFlow's desktop interface via the Advanced --> System menu.
Mobile Interface
OrderFlow features a mobile application optimised for display on small handheld devices such as smartphones. This application is designed primarily to display Key Performance Indicator (KPI) reports and other dashboard reports.
This feature is at an early stage of development.
The next two chapters provide an overview of OrderFlow's Order Processing and Warehouse Management capabilities, with illustrated examples.
Order Processing
One of OrderFlow's most fundamental functions is Order Processing, which includes the pick, pack and despatch of orders.
OrderFlow can process orders from multiple organisations and multiple sales channels within organisations. It can restrict a user's access to certain organisations and channels, so that users can only see the orders that are relevant to them.
Additionally, OrderFlow is a multi-site system, which means that it supports the fulfilment of orders across multiple warehouses and all that this entails.
This chapter tracks a typical order as it is processed through the OrderFlow System. This is a simple example for illustration purposes only. See the Further Reading section, below, to find out more about the depth of OrderFlow's capabilities.
Terminology
Orders and Shipments
Throughout this chapter, reference will be made to orders, order lines, shipments and items. The relationship between these is as follows:
- An order is made up of one or more order lines, to be despatched to an end user at a residential or business address.
- An order line is a product being ordered, in the quantity required.
- Order lines from the same order can be despatched in one or more shipments.
The usual case is that an order will be despatched in just one shipment.
(Shipments are despatched via a courier.) - A shipment with only one order line is called a single-line shipment. A shipment with more than one order line is called a multi-line shipment.
- Items are the individual products within an order line.
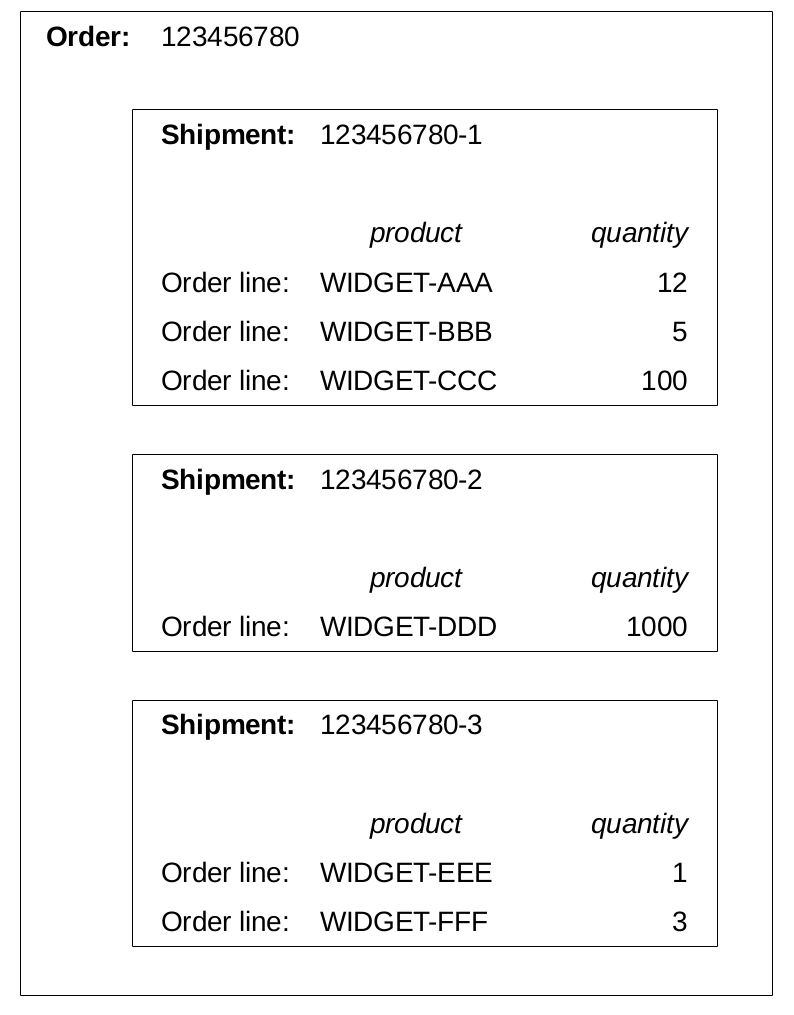
The diagram below shows a multi-shipment order 123456780, which contains three shipments. Shipment 123456780-2 is a single-line shipment, whereas the others are multi-line shipments.
States
OrderFlow uses states to monitor and control an order's progress through the system workflow. Orders, shipments and order lines can have various states, and a shipment can have additional states that signify its progression with its courier.
As an example, when an order is imported into the system, by default the order is validated, the order lines have a state of created and the shipment is ready. When all items in an order have been shipped, the order lines have a state of packed, while the shipment(s) and order are despatched.
There are many states that can be used for shipments as they progress through OrderFlow. Some environments may also use custom states. The transition between states is configurable, so there is no definitive state transition diagram that can be presented. However, a typical shipment state transition is shown below, alongside a typical shipment courier state transition:
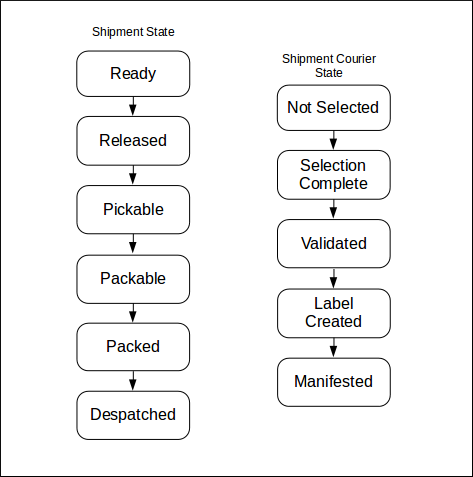
Note that some states of the states are terminal states. For example, the despatched and cancelled shipment states are terminal, as there is typically no further work to do on a shipment when it reaches this state. Shipments, orders and other entities that are not in a terminal state are considered open.
An Order Processing Example
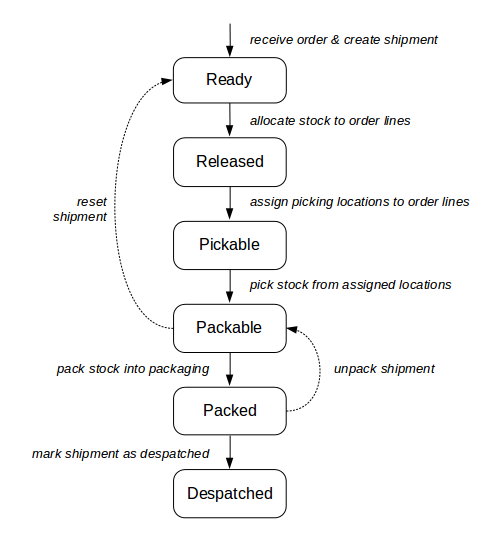
For an order to progress through a typical despatch workflow, various things need to happen to it. Firstly, the required stock needs to be allocated to its order lines, then the specific items in specific locations need to be assigned to these order lines.
Once specific stock has been assigned, that stock can be picked by a warehouse operator. This can be directed by a paper report, generated by OrderFlow, or by a handheld device that the warehouse operator (called a 'picker' in this case) carries around with them.
Once a picker has picked all the items for the order's shipment(s) (or more typically, a batch of shipments at a time), they can present the stock they have picked to a packer. The packer's responsibility is to check the items are correct, in the right quantities, and pack them using the required packaging, ready for despatch. The packer will also usually include a despatch note, which details the items in the shipment, for the recipient to read and check.
At some point during this process, OrderFlow will determine which courier should be used to despatch the shipment, based on scripted configuration. It will also print a courier-specific despatch label to attach to the shipment. It may interact with the courier's system at this point, to inform it of the details of the shipment, and to get a despatch reference in real-time.
Once the courier turns up and takes all the packed shipments away for delivery, they can be marked as despatched in OrderFlow.
In the next sections, some of these steps are described in a bit more detail.
Order Receipt
Orders which have been imported (i.e. have been transformed and validated - see the Advanced section for more details), can be viewed on the Orders Dashboard which is accessed from the 'Despatch' tab.
For most users, the Orders Dashboard will be used only to view and search for Orders, as most orders are automatically imported and validated by OrderFlow. However there are some cases which may require manual validation, for example, orders for different countries, orders which exceed a certain value, etc.
OrderFlow has to decide how many shipments will be required to fulfil the order. This decision will be based upon various factors, including where (in a multi-site environment) the stock resides for the order lines, since some products may only be stocked in some warehouses. Other factors when deciding whether to split an order into multiple shipments may include product lead time, product weight, or any special carriage requirements (e.g. an out-sized product).
The normal case is for an order to have just one shipment.
The next stage is to allocate the order lines with stock. Only order lines that belong to an order in the validated state can be allocated stock.
Stock Allocation and Assignment
OrderFlow is capable of using two types of fulfilment model - the Stock-based Fulfilment model or the Just-in-time (JIT) model.
In the majority of cases, OrderFlow automatically allocates stock using the the stock-based fulfilment model, which is described here. For details of the Just-in Time (JIT) fulfilment model, see the Just-in Time Fulfilment section, below.
When using the Stock-based Fulfilment model, OrderFlow employs a two-stage process for identifying the stock that can be used to despatch orders.
Stock allocation is the process for identifying whether there is stock present in the warehouse to fulfil the order lines in a shipment. Stock assigment is the mechanism by which stock in specific locations are reserved for picking the stock required for these order lines.
These are discussed in turn below.
Stock Allocation
Stock allocation is performed on a line by line basis for orders that are waiting to be despatched. Based on the priority of the outstanding shipments, and other criteria, OrderFlow determines, for each order line, whether there is sufficient stock in the warehouse to meet the order line's stock requirement.
If there is sufficient stock, the order line is given a state of allocated. If there is a shortfall, the order line is given a state of out of stock.
The state of each order line can be viewed from the 'Lines' dashboard, which is accessed from the 'Despatch' tab.
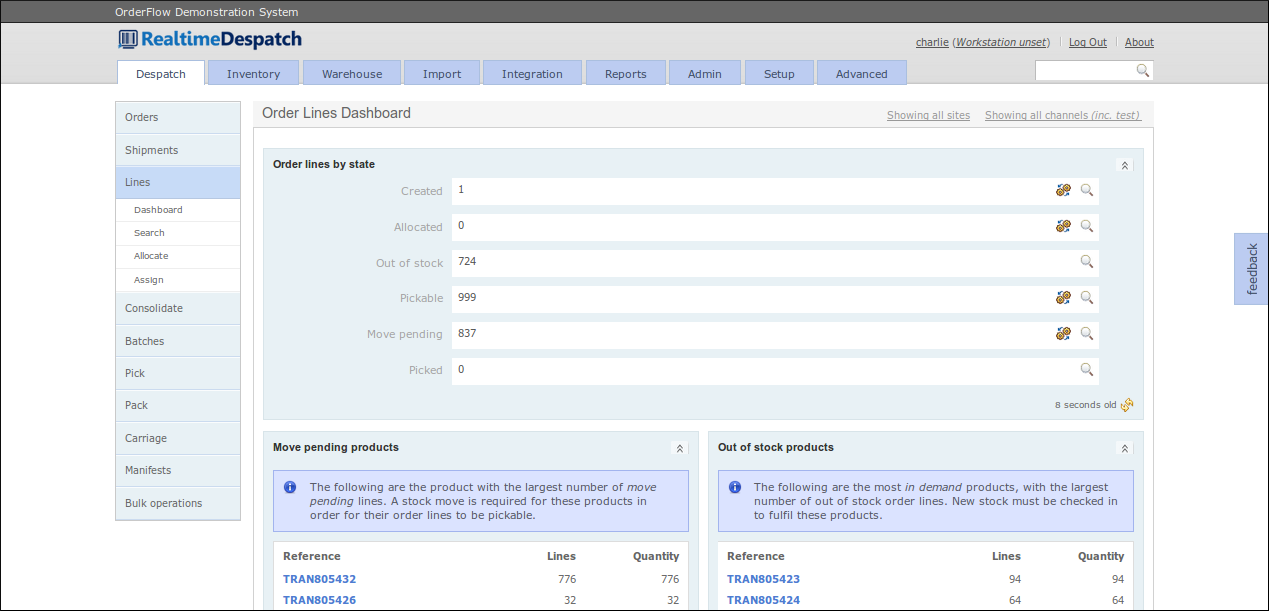
A shipment's state can be automatically updated, based on the state of its order lines. For example, if all order lines for a shipment have a state of allocated, the shipment is progressed to a state of released.
If one or more order lines for a shipment have a state of out of stock, the shipment is given a state of out of stock.
The state of each shipment can be viewed from the 'shipments' dashboard, which is accessed from the 'Despatch' tab.
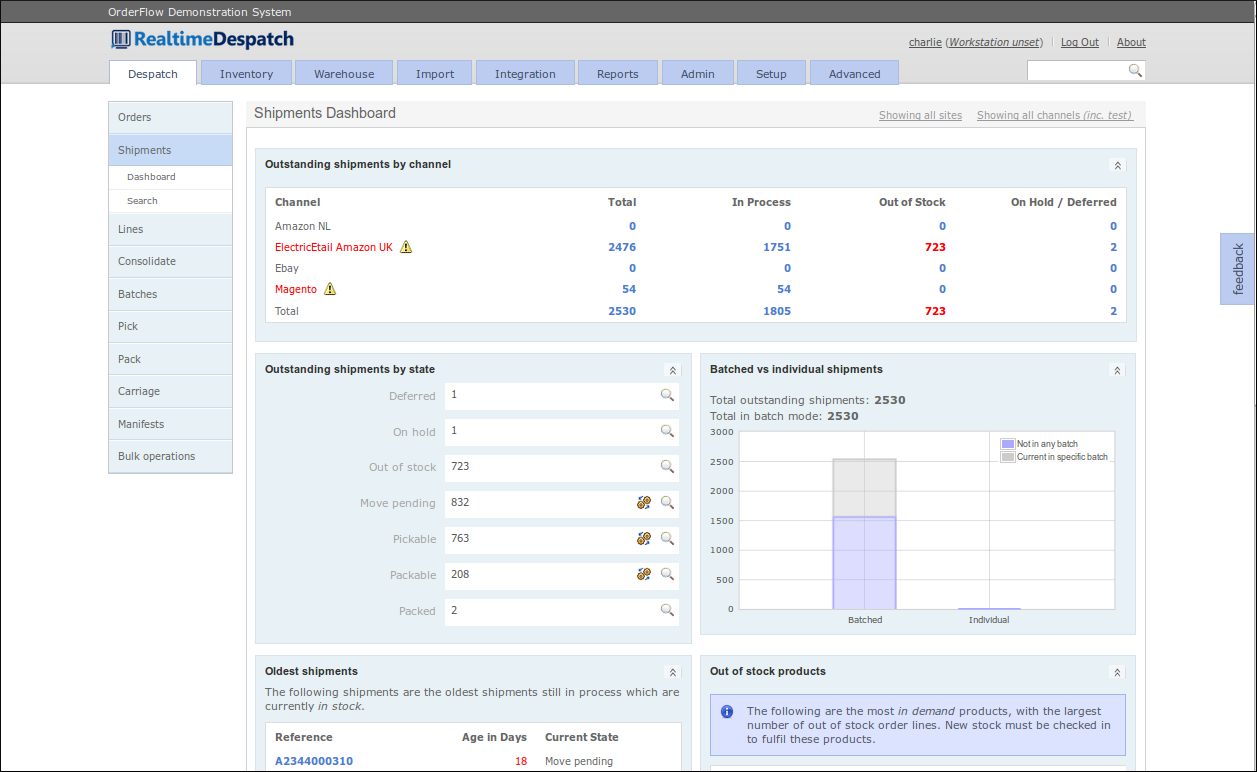
The next stage is to assign specific picking locations for a shipment's order lines. Only shipments that have a status of released can have their order lines assigned.
Stock Assignment
In the majority of cases, the OrderFlow system automatically assigns stock.
Stock assignment is the process of reserving specific stock in the warehouse to fulfil the order lines in a shipment. OrderFlow attempts to identify picking locations and quantities that match the stock requirement for the order lines concerned. If a picking location can be found for an order line, the order line is given a state of pickable.
If all order lines for a shipment have a state of pickable, the shipment is given a state of pickable.
In some cases, picking locations cannot be found for certain order lines. Typically, this means that additional warehouse operations are required before certain order lines can be picked. For example, some of the stock required may only be present in non-pickable locations, such as bulk storage or incoming locations. In this case, it must be moved to the correct location before it can be picked. In these cases, order lines and shipments are given a state of move pending.
The next stage is to physically pick the stock. Only shipments that have a state of pickable can be picked.
Shipment Picking
OrderFlow provides many options for physically picking stock. These options can be broadly categorised into paper-based picking and handheld-driven picking.
Paper-based picking involves grouping pickable shipments into batches, and printing out a picking list (for each batch) that contains all the information needed for a 'picker' to go to the correct warehouse locations and pick the correct quantities of stock for all the shipments in the batch. For more details of batch picking, see the Batches section, below.
Handheld-driven picking requires OrderFlow to direct a 'picker' to each picking location via the handheld interface. At each location, OrderFlow instructs the picker how many units of which product to pick. One of the advantages of this method of picking is that the picking can be dynamically controlled, with the most optimal picking route determined 'on the fly'. Another advantage of this method is that the real stock position is reflected in real time in OrderFlow.
The picking state and picking locations of each shipment can be viewed from the Picking dashboard which is accessed from the 'Despatch' tab.
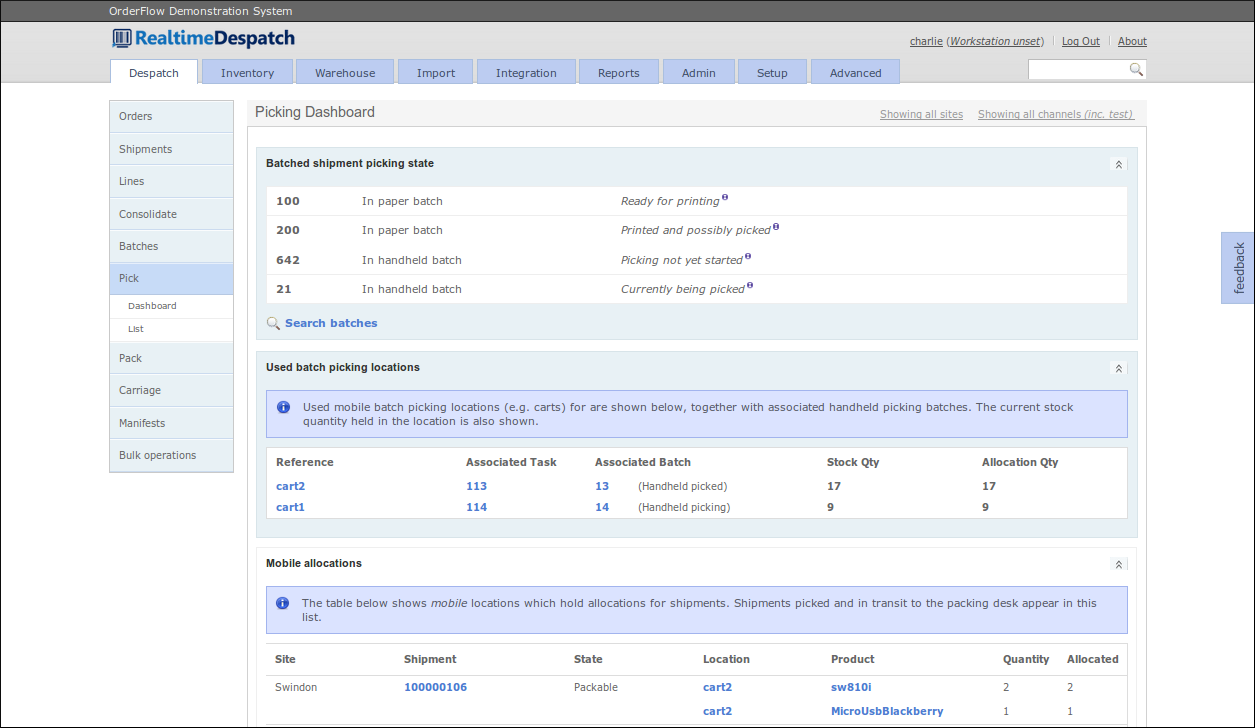
Once a shipment is picked using whatever option OrderFlow is configured to use, it is usually given a state of packable.
The next stage is to pack the stock. Only shipments that have a state of packable can be packed.
Batches
A Batch is a grouping of shipments that are picked together. Organising shipments into batches can fulfil a number of purposes.
- related shipments can be grouped together to support a simpler or more efficient picking operation. For example, single-line shipments can be picked more efficiently than multi-line shipments, so it makes sense to pick them together. Also, it can often be more efficient to pick together shipments that share the same priority or courier.
- for paper-based picking processes, a consolidated picking list can be printed for all of the shipments in the batch. It also makes sense in some cases to also print all of the customer paperwork (despatch notes or invoices) as part of a batch print operation. This can greatly save on time that would otherwise be required for per-shipment print jobs. This requires the use of high-end, fast printers, but allows for the preparation of paperwork in bulk as part of a background task.
- batches can also be used to support particular workflow processes. The obvious example is picking, either with the help of paper reports or handheld terminals. In some cases, other batch operations can be supported, such as marking all shipments in a batch as packed or despatched.
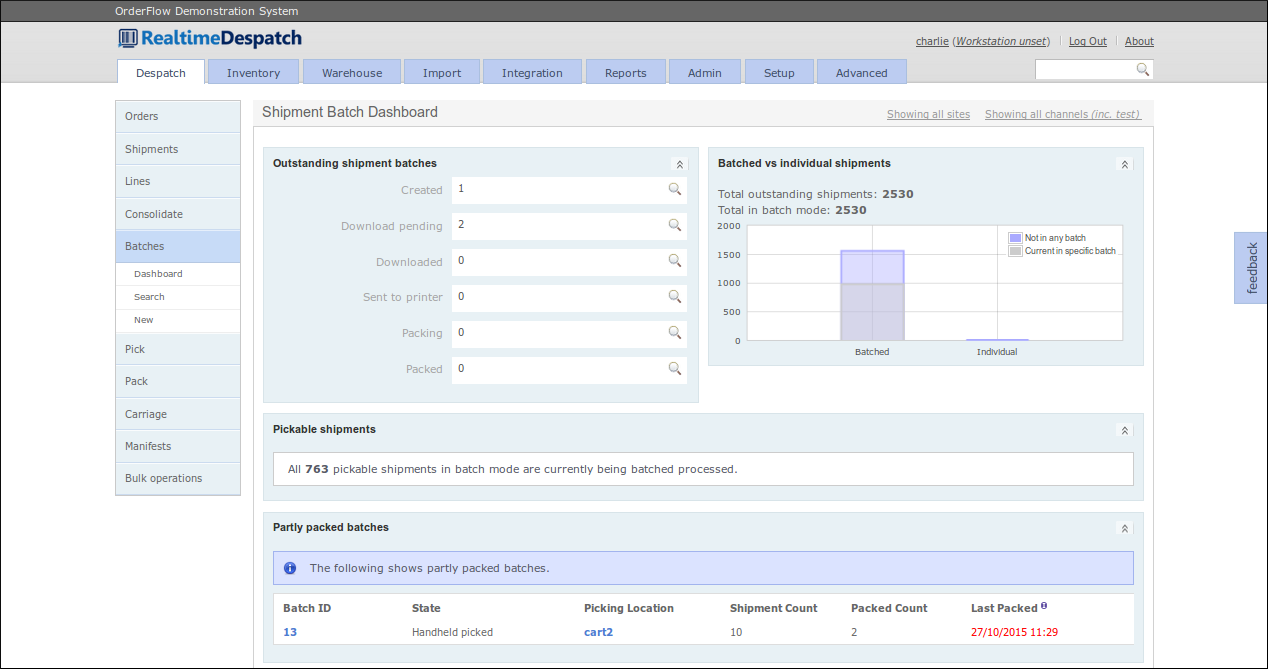
Shipment Packing
OrderFlow supports many different ways to pack shipments.
The most simple way is to simply mark all shipments in a batch as 'packed'.
This is effective if the batch is paper-based and the shipment paperwork
(including integrated courier labels) was already generated and printed before
the batch is picked. In this case, a 'packer' would simply place the correct
stock in the correct shipment packaging, and inform OrderFlow that all the
batch's shipments have been packed. OrderFlow would have to trust the packer
to put the correct stock in the correct packaging. (Note that this may
constitute several packages.)
Some organisations want tighter control over packing, i.e. they want to be sure that no mistakes are made during the packing process, which would result in the wrong goods being despatched. This may be the case if they stock many different products, or if products are very similar and can't easily be distinguished by eye.
In this case, OrderFlow can be configured to require the packer to scan the items in a shipment before it can be marked as packed. (This process is known in OrderFlow as packing consolidation.) This unambiguously identifies the products and immediately flags any unexpected products (and indeed any incorrect quantities) to the packer. Only when all the correct products in the correct quantities have been scanned can a shipment be marked as packed. This is achieved from the 'packing screen' in OrderFlow.
Another reason that OrderFlow may require the packer to access the 'packing screen' for a shipment is that the courier label may need to be printed separately from any customer paperwork. (This is especially the case if a desktop courier system is being used - see the Courier Integration Guide for more details.) In this case, the courier label would typically be printed on a thermal printer local to the packer's 'packing station' (i.e. PC).
The packing operations on OrderFlow can all be controlled from the menus under the 'Packing' dashboard:
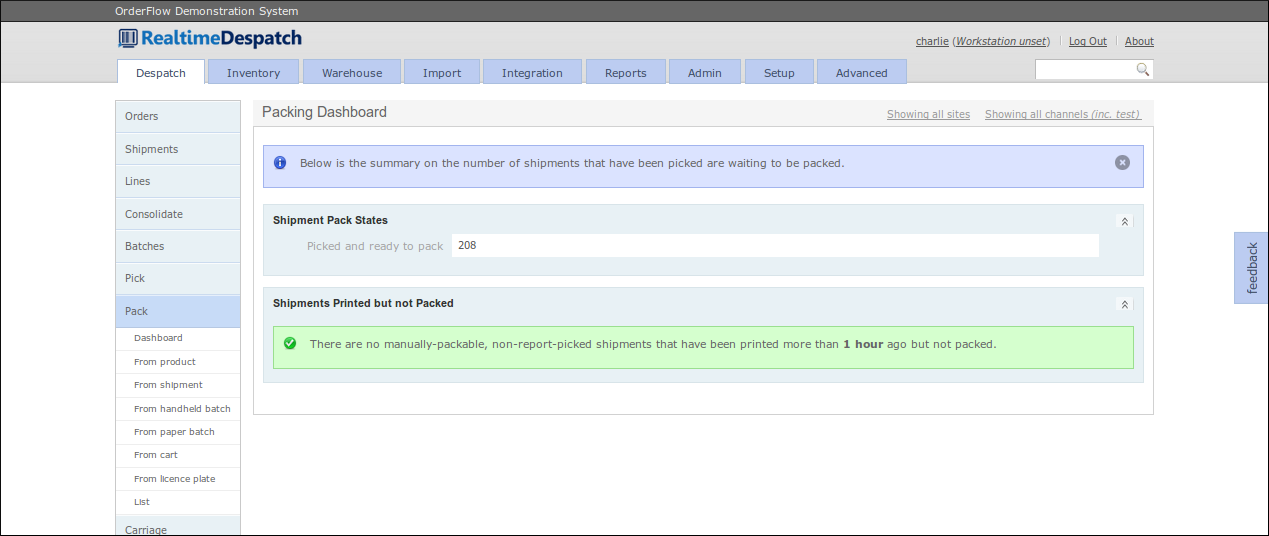
As part of the 'packing consolidation' process, OrderFlow supports other refinements, such as requiring the packer to scan a product's batch code, or to supply a quantity instead of scanning every product.
Typically, once a shipment is packed, the stock is debited from the warehouse. OrderFlow can be configured to perform this action later on, at shipment despatch time, if required.
Once a shipment is packed it is given a state of packed.
Courier Selection
In parallel with getting the stock ready for each shipment's despatch, OrderFlow progresses the selection of an appropriate courier for the shipment, to facilitate the actual shipping of ordered items directly to an end user's address. The 'Carriage and Delivery Dashboard' provides information relating to this:
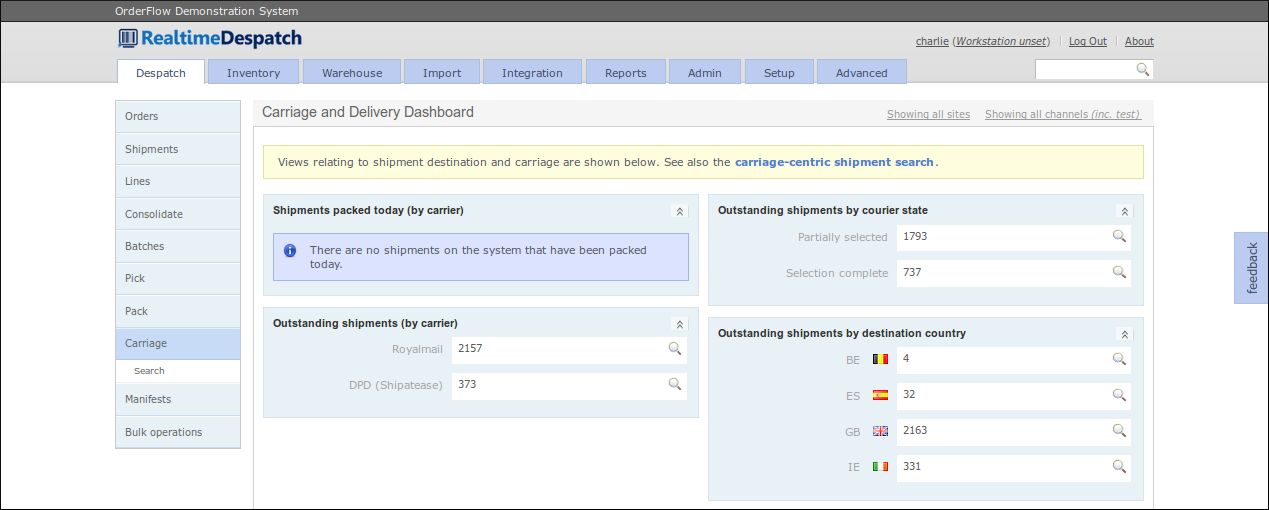
A courier can be selected in two ways:
- manually: the user explicitly chooses a carrier and service from one of the available choices, or
- automatically: via the application of a 'Courier Selection' script at some point in the shipment's progression through the workflow.
A courier for a shipment can be selected at any time from the Receive Order to Pick shipment stages. When a courier can be selected in the process is configurable.
Automatic selection via script can use any of the shipment or order's attributes to determine which courier, service and options to use. For example, the shipment's destination and weight, and the priority of the order may influence this selection.
If no courier selection has been made at the point of packing, the user will typically be redirected to a manual courier selection screen before being allowed to proceed to the packing screen. An example of this screen is shown below. Depending upon the courier and service selected, there may be additional validation that needs to be performed, which may involve real-time communication with a courier's system.
The 'courier state' of a shipment is progressed separately to the shipment state.
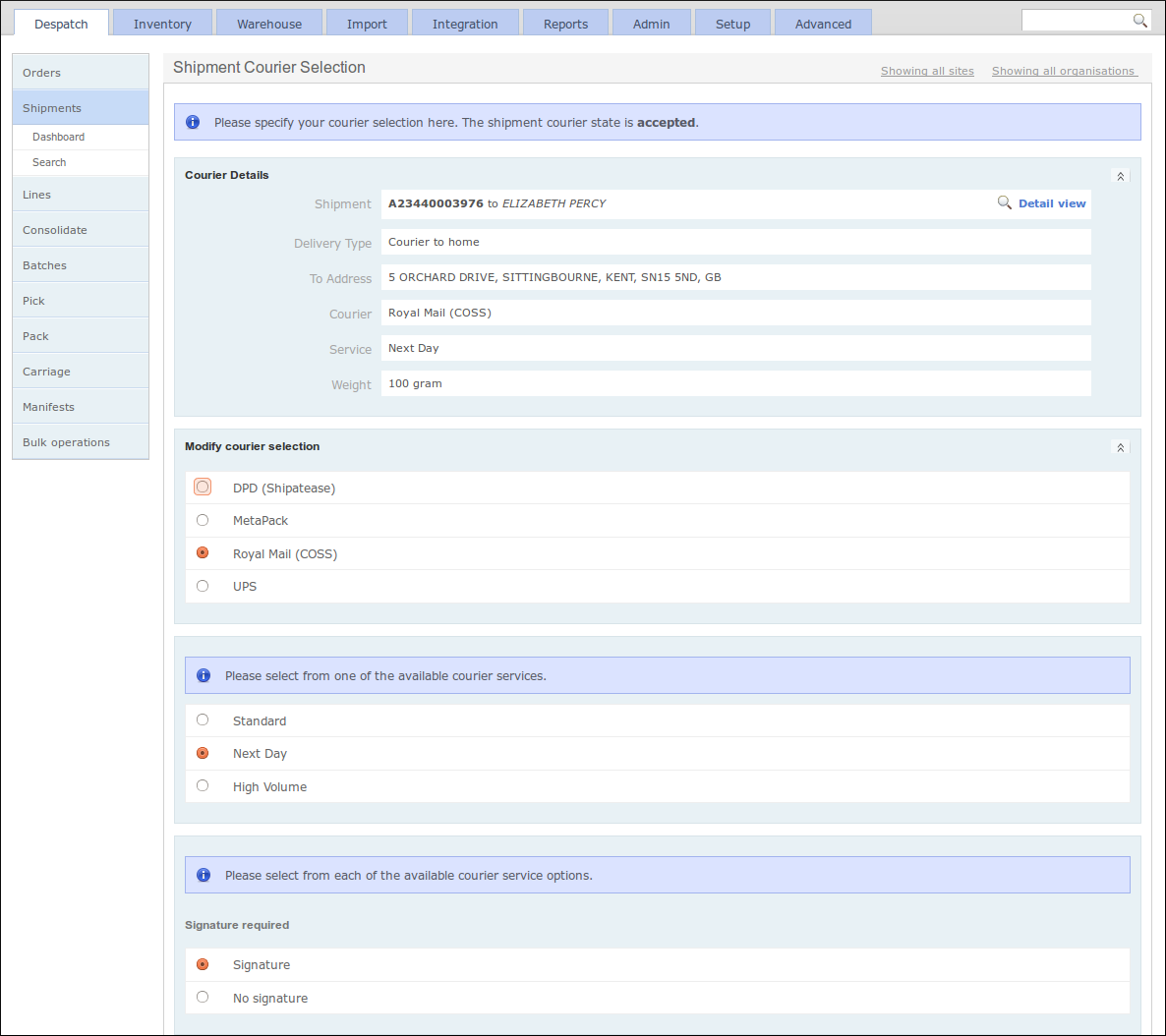
Just-in Time Fulfilment
The objective that underpins JIT fulfilment is to minimise the necessity to hold and double-handle stock and, where possible, to fulfil outstanding orders directly from stock received through incoming deliveries.
There are significant differences between the way that OrderFlow applies JIT fulfilment for single-line versus multi-line shipments.
- for single-line shipments, it is normally possible to send received stock directly to the packing area as soon as they come in. So no storage of these products is required at all.
- for multi-line shipments, temporary storage of the incoming stock is required. This is because the stock for the different order lines will be received at different times, possibly through separate deliveries and from separate suppliers.
Therefore for multi-line shipments, a pure JIT approach is not possible, because order lines for multiple products must be consolidated before the shipment can be shipped. OrderFlow achieves this through a JIT consolidation process. Items received are held in shipment-specific temporary storage locations in a consolidation area. These are normally close to the incoming and packing areas of the warehouse. Once all of the stock for all of the lines in a multi-line shipment have been consolidated in the single location, the shipment can be picked and packed. For more details of the consolidation process, see the Consolidation section, below.
One variation of the JIT model for multi-line shipments involves fulfilling items partly from stored stock. For example, if some stock for out-of-stock multi-line shipments is present in the warehouse, it is possible to consolidate the shipment order lines partly from incoming stock via the JIT process, and partly from stored stock.
Consolidation
Consolidation in OrderFlow refers to the process of the temporary storage of some of the stock for a multi-line shipment, usually in the absence of all of the stock.
Typically, an OrderFlow warehouse that supports this process will have a
'consolidation area', which will contain many consolidation locations.
Depending upon the size of the products, a consolidation location may be a
pallet, a shelf or a 'pigeon hole'. Each consolidation location will be
associated with at most one shipment at a time.
Stock for a multi-line shipment will get directed to the specific consolidation location for that shipment, as it becomes available. (This could be as a result of an incoming delivery, or because of a stock move from bulk storage.)
Once all the stock for a shipment is present in the consolidation location, the shipment is considered to be 'consolidated'. OrderFlow then marks it as pickable, which means it can then be picked and presented to a 'packer'.
When a consolidated shipment is picked from a consolidation location, the location is empty and can then be re-used for another consolidating shipment.
The 'Consolidation' dashboard shows the state of consolidating shipments in OrderFlow. The 'Consolidation Locations' screen below shows the consolidation locations in use.
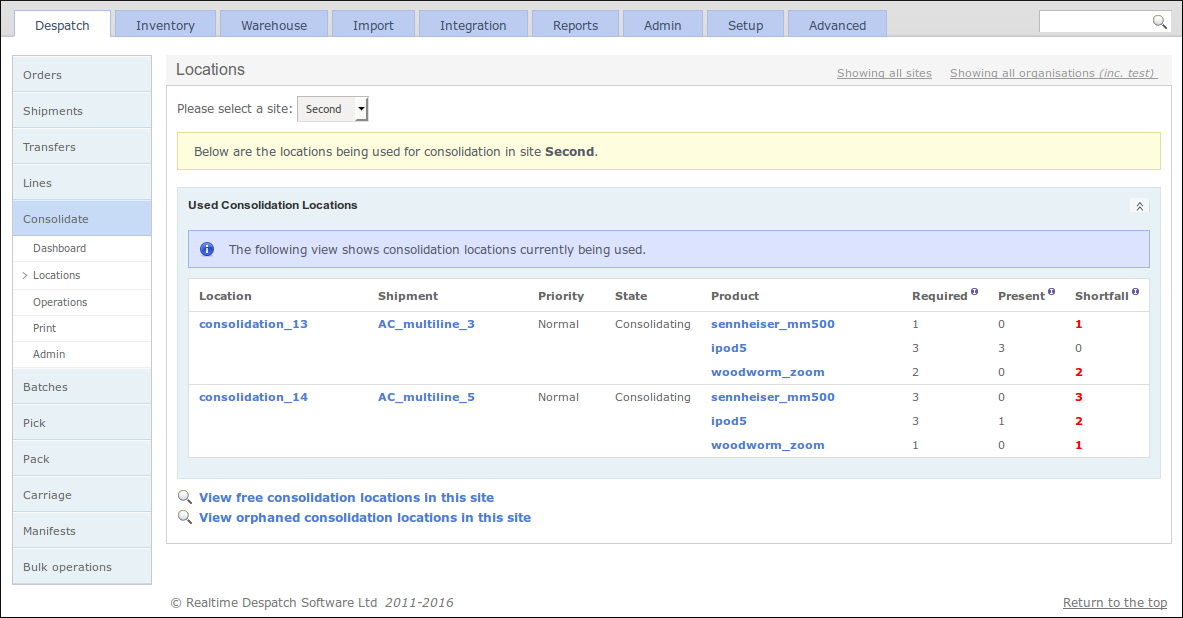
Further Reading
Warehouse Processes Guide (to be published)
Warehouse Management
OrderFlow has user-friendly Inventory and Warehouse functions which make it easy to manage stock in an efficent and cost-effective way.
Stock can be placed in any number of different locations in a warehouse. In OrderFlow, these locations can be configured to be of various types that allow for fine-grained usage and control. For example, locations such as shelves, pallets, picking carts, totes, fridges, consolidation 'pigeon holes' (and so on) can all be created.
Locations can be assigned to areas within a warehouse, to allow for easy compartmentalisation of the available warehouse space. For example, locations can be defined as picking locations, bulk storage locations or quarantine locations.
This chapter describes how OrderFlow manages the stock in locations, and how it makes such stock available for various warehouse operations.
The diagram below shows a simple example warehouse layout, using OrderFlow terminology. The shaded areas denote locations.
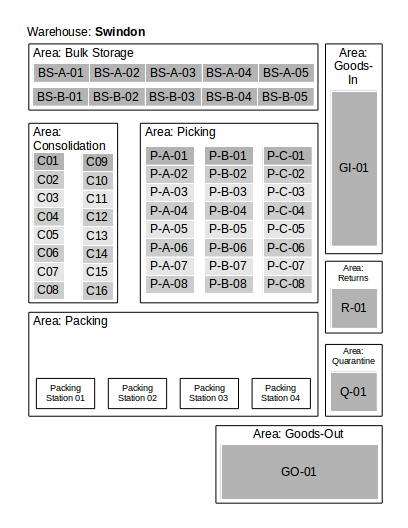
Terminology
Throughout this chapter, reference will be made to sites, areas and locations. The relationship between these is as follows:
- A Realtime Despatch customer will have one or more sites; a site typically being an individual warehouse.
- A site is made up of one or more areas.
- An area is made up of one of more locations.
Locations
A location is simply a defined place in a site where stock can reside.
Locations can be configured to hold stock for just a single product, or they can be configured to contain units of multiple products. OrderFlow enforces such restrictions throughout.
Locations can be configured to have a number of different attributes, such as aisle, bay, level, position, side, dimensions. They can also be given various indicators to allow them to be ordered in different ways for different purposes, such as picking, replenishment and stock checking. (More on this later.)
Locations are defined to be of specific Location Types.
Location Types
OrderFlow categorises locations into different types, to help it manage the flow of stock more easily. Location Types are configurable entities that can have any combination of various defined attributes. This allows for fine-grained control of how locations are used, particular to the specific customer needs.
There are many attributes of a location type - some commonly-used ones are detailed here:
- pickable: Determines whether this location can be used as a source location for picking operations. If stock is only in non-pickable locations, then replenishment of picking locations must occur before picking can proceed.
- storage: Indicates that the location can be used for storage. Only storage locations will typically be considered as target locations for putaway operations.
- multiProduct: Indicates that a location is designed to contain multiple products.
- incoming: Used specifically for locations for receiving incoming deliveries.
- damaged: Used to hold stock that is considered to be damaged.
- mobile: Used for locations which do not have a fixed physical position in the warehouse. Physically, may be a cart, cage, trolley, tote or some other mobile container. Used extensively in handheld scanner-based operations.
Products
Products are the shippable goods that are received into the warehouse via deliveries, stored in locations, and sent out in shipments following the receipt of orders into OrderFlow.
Products are usually counted in units and generally referred to as stock (when talking about physical instances of a product).
Products can be categorised according to physical attributes and also logically typed. For example, an 'instruction manual' product could be categorised as a 'book' of 'default' type, whereas a 'tool kit' product could be categorised as a 'tool' of type 'bundle'.
Typical products types are:
- default: A sellable stock-based product, eligible for stock notifications
- virtual: A virtual product, for which no stock is held, but is sellable. No fulfilment for a product of this type is required.
- bundle: A bundle is sellable product which is composed of underlying (typically) stock based products. It is also a virtual product in the sense that there is no physical representation of the bundle, only the underlying constituent products.
Inventory
The term 'inventory' is used in OrderFlow to mean the overall view of the stock position, without going into detail as to exactly where that stock resides.
For example, if a product is held in differing quantities in many different locations in a warehouse, the inventory for that product would include the total number of units across all those locations.
The inventory would also detail how much of that total quantity was usable, (i.e. excluding any damaged or quarantined stock), and how many units of that product were required by pending order lines.
The available quantity can be derived as the usable quantity less the required quantity. Note that this can be negative if there is insufficient stock in the warehouse to fulfil all order lines for that product. (Such a negative amount is called the shortfall of a product.)
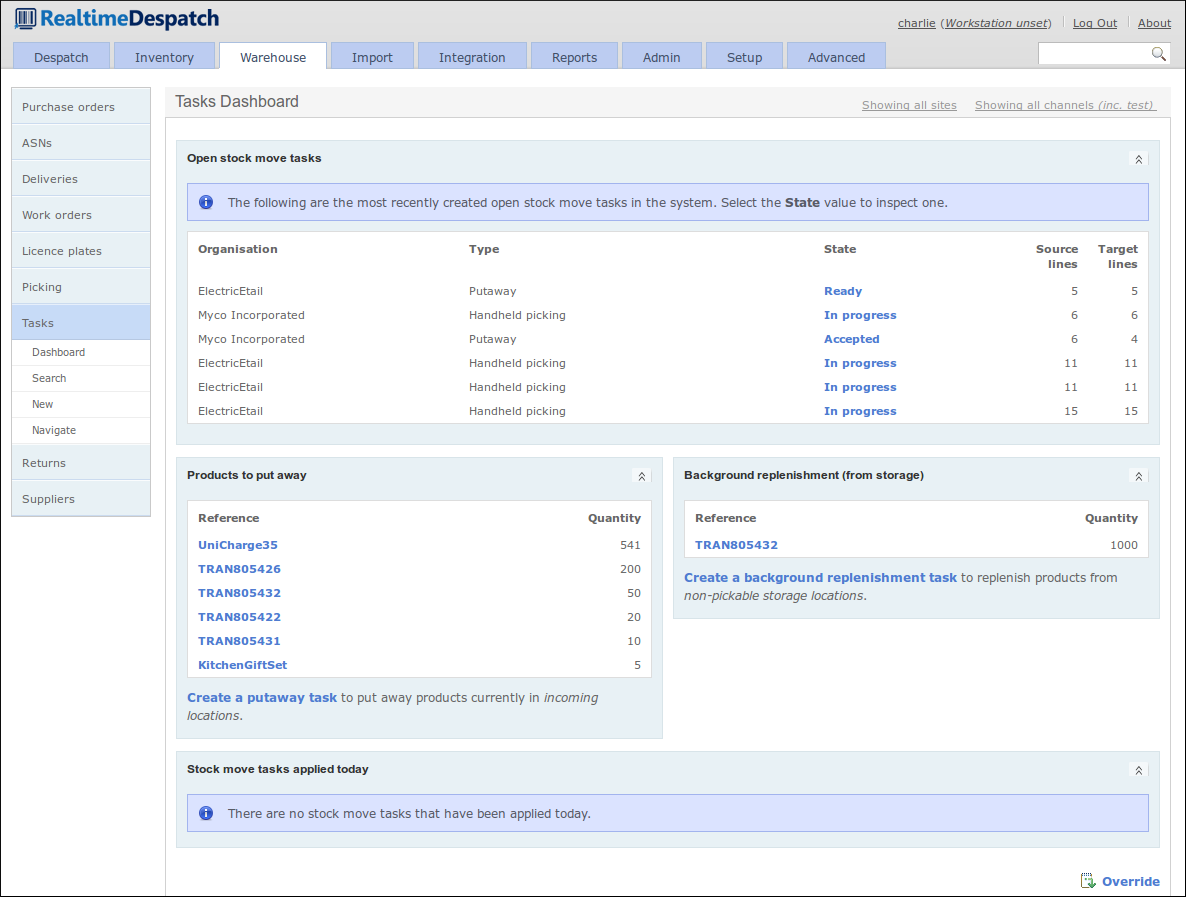
Tasks
Stock move tasks are used by OrderFlow to manage many warehouse processes. These are essentially instructions to move explicit quantities of products from one location to another. They are also used internally to drive certain processes.
There are many different types of tasks - some of these are listed here:
- putaway tasks: where stock is moved from incoming delivery bays to storage locations.
- replenishment tasks: where stock is moved from bulk non-pickable storage locations to pickable locations.
- picking tasks: the process of picking stock to fulfill orders, especially when using a handheld terminal.
- consolidation tasks: used when multiline shipments are routed into a consolidation area prior to packing.
When a stock move task is executed and applied, stock changes are created in OrderFlow. These are immutable records whose purpose is to preserve an audit trail of "what happened when".
Warehouse Management Features
This chapter describes the most commonly used stock management features provided by the OrderFlow system.
Goods In
In day-to-day warehouse operations, stock is added to the warehouse through the receipt of a delivery. A delivery is the arrival of physical goods at the warehouse door.
OrderFlow represents this operation as a 'Delivery' object, which may or may not have 'Delivery Lines' attached, depending upon whether the contents of the delivery are known in advance.
The contents of a delivery may be known in advance if OrderFlow is informed of an Advanced Shipping Note, or indeed if the delivery is in direct response to a Purchase Order. More details about these concepts can be found in the Warehouse Processes Guide.
If the contents of a delivery are not known, then the items in the delivery are scanned and quantities confirmed. OrderFlow then creates the delivery lines from the supplied information.
Once a delivery is applied (either incrementally or in one go), the stock in OrderFlow is credited. The delivery detail page (shown below) shows all delivery-related information.
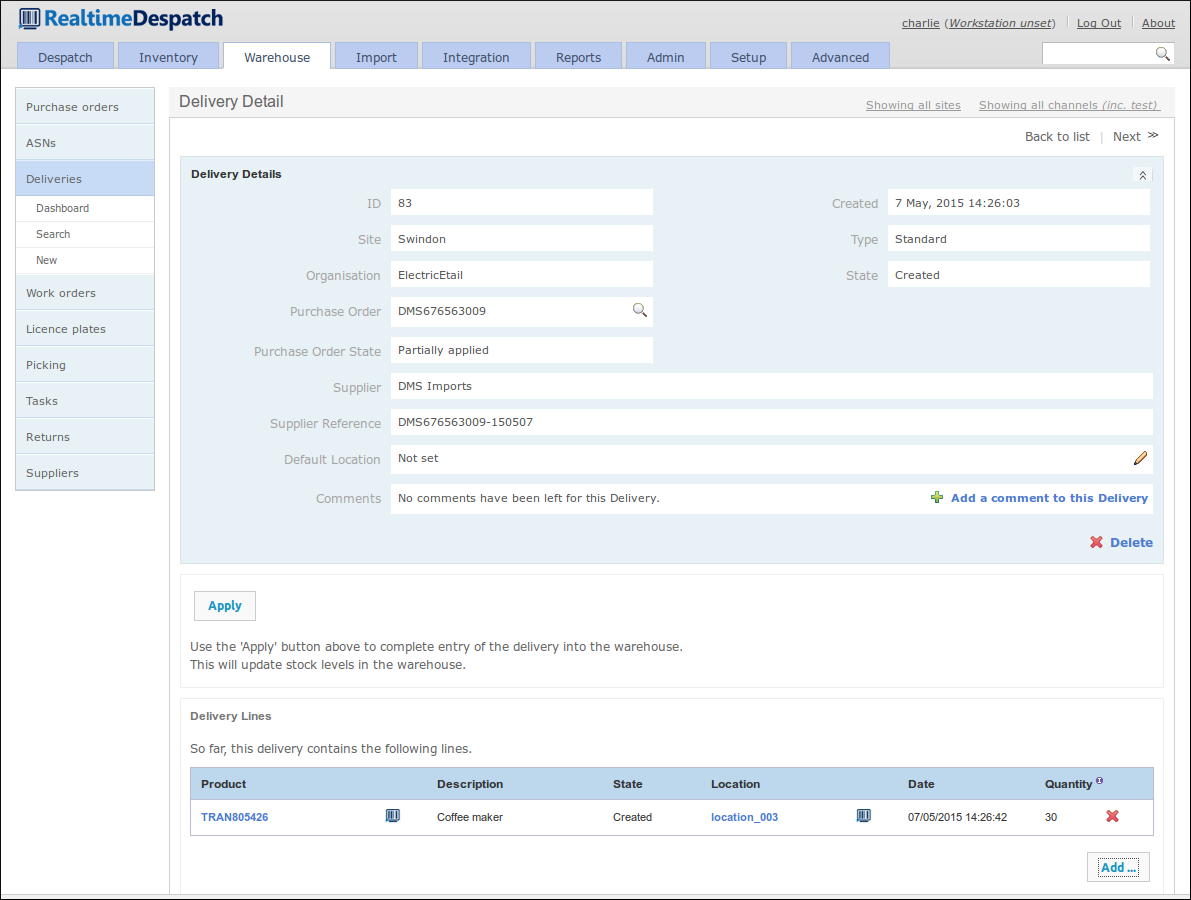
The stock credited to OrderFlow can be handled in various different ways. The most simple is for it to be credited to an incoming location and then put away to pickable or storage locations. This is achieved via a stock move task, detailed in the following section.
More complex methods of processing delivered stock include routing straight to packing (cross-docking), to consolidation, or a combination of these (and more). More details on this can be found in the Warehouse Processes Guide.
Stock Move Tasks
At their most basic level, stock move tasks are simply instructions to warehouse operators to move one or more products from one or more source locations to one or more target locations.
They can be used for all sorts of processes - the simplest being putaway or replenishment processes, where stock is routed to or from storage locations (respectively). (Putaway processes can also route stock to pickable locations.)
Stock move tasks are also be used to drive the picking process - even dynamically when handheld devices are in use. Other common uses of stock move tasks include routing stock from storage to consolidation locations.
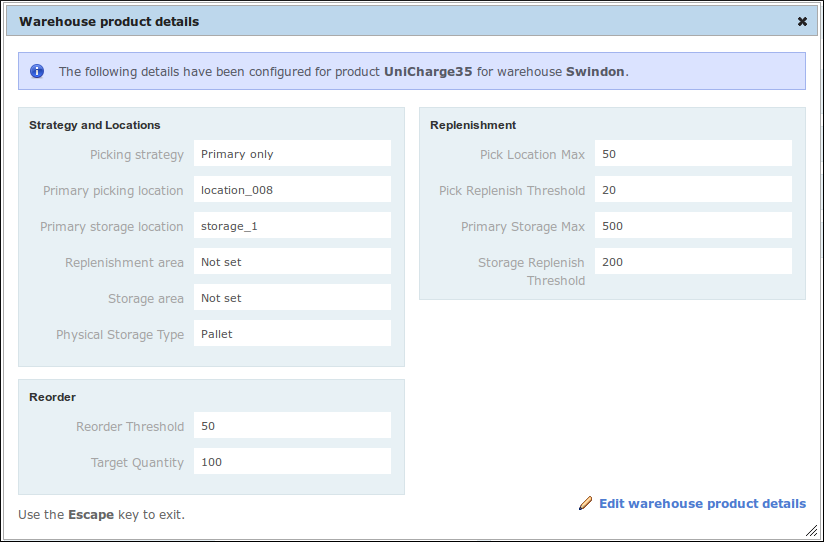
Storage, Replenishment and Reordering
Products in OrderFlow can be configured to have specific attributes, that allow their movement and behaviour to be finely controlled. These setting can be applied per site, so different behaviour can be applied to different warehouses.
For example, a storage area or a more specific storage location can be defined for a product, which directs OrderFlow where to put away stock for this product.
Similarly, a primary picking location can be set, which restricts the typical picking processes to that location. In this case, replenishment of stock from storage location(s) to the primary picking location must occur before this product can be picked.
Also, a reorder threshold can be set for a product, which defines the minimum number of product units that are held in a warehouse before it is included in a reorder report. This will ultimately result in the product being included in a purchase order which, when imported into OrderFlow, will show the product as being 'on order'.
The following screenshot shows the 'Warehouse Product' configuration details that can be applied:
Returns
When the recipient of an order returns a product (or products) for any reason, they usually send those products back to the warehouse from where they were despatched.
OrderFlow supports processes to allow these goods to be checked back into (typically) a quarantine location, ready for whatever reconditioning or repair needs to take place before returning to stock. Sometimes the goods have to be sent back to the original supplier, so will not be returned to the normal storage / pickable stock for re-use.
This 'returns' process allows the user to record the condition of the returned goods, the customer's reason(s) for returning the goods, and (possibly) whether they believe a refund should be paid. The following screen shot shows the detail of a return line:
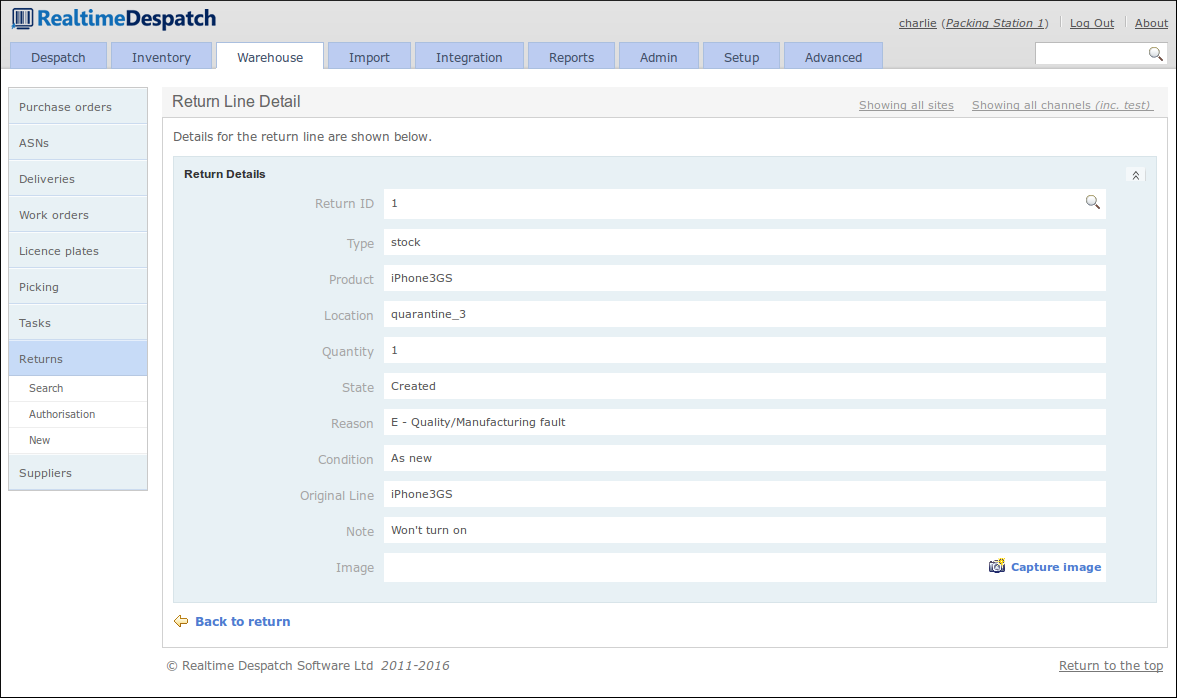
Further Reading
Warehouse Processes Guide (to be published)
Advanced Features
OrderFlow has many other features that have not yet been covered in this document. This section aims to introduce a few of them, guided by their position in the desktop user interface.
Import
As we have already seen, OrderFlow has the potential to require a large amount of configuration data in order to support the more complex warehouse layouts and processes. Keying-in this configuration data would be time-consuming and prone to error, so it is made possible for such setup / configuration data to be imported from spreadsheets etc.
In addition to configuration data, transactional data such as orders needs to be imported, again to avoid having to key-in such data. OrderFlow supports many different data import mechanisms and formats, with the aim of being flexible enough to integrate with other systems with the minimum of effort.
For example, it is possible to import orders from comma-separated value (CSV) files, spreadsheets, or richer data formats such as XML or JSON. Imported data can be automatically transformed into more-expected formats so that OrderFlow can process it more easily. OrderFlow can be pushed orders from a client that uses OrderFlow's application programming interface (API), or that places files on its FTP server, for example. Alternatively, OrderFlow can be configured to pull orders from a remote system (e.g. a shopping cart).
The history of all import attempts, both successful and failing, are recorded in OrderFlow's import history, so that it is always possible to view how data arrived on the system. The screenshot below gives an example of such a history.
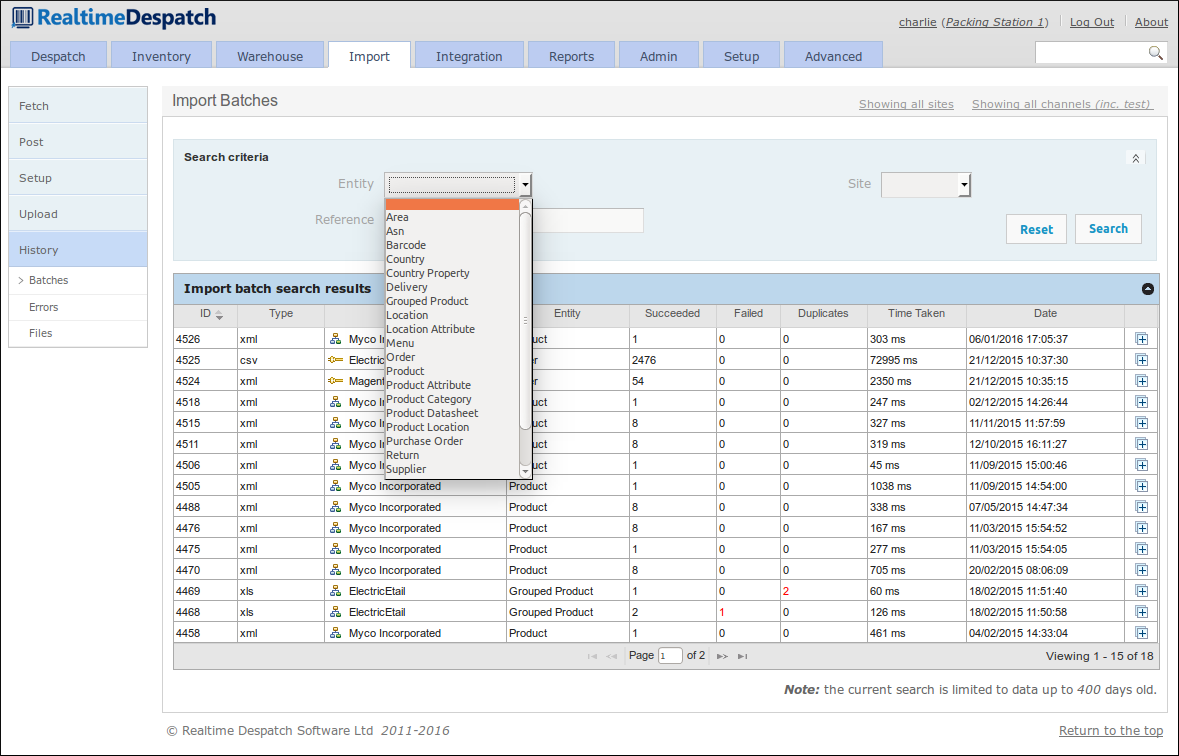
Integration
The Integration area of OrderFlow primarily deals with communications with external systems, both at the message level and at the application programming interface (API) level. It also holds the configuration for some of OrderFlow's internal processes, allowing them to be changed without the need for a new version of the codebase.
Remote Messages
The Remote Messages area of OrderFlow deals with communications with external systems. It shows all messages sent to external systems, and their corresponding responses.
Each remote message is of a certain message type, which is a configurable object that provides flexibility to have fine-grained control over how these messages are sent, and what the responses mean.
For example, an 'inventory notification' message type can be configured to
be sent over HTTP, with a maximum of 5 retries, and that a successful message
is one with HTTP response codes 200 or 401. Additionally, the response body
must not contain the text '
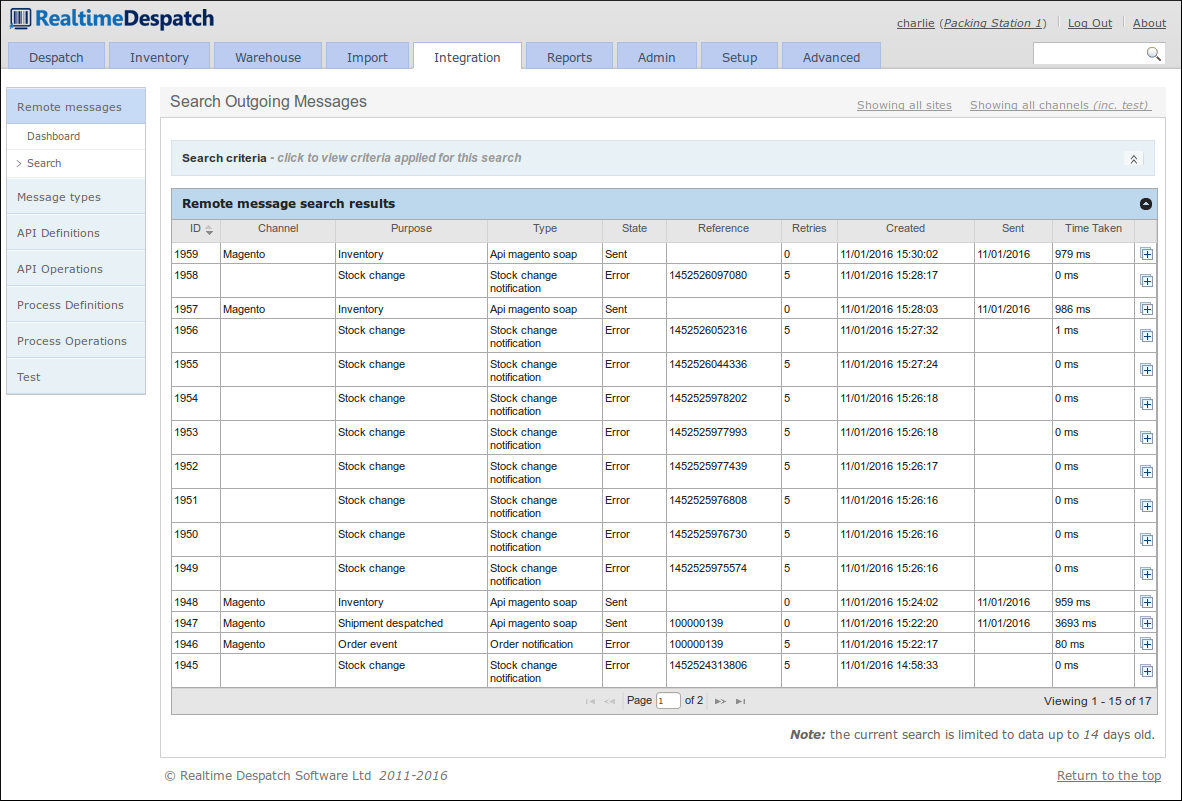
API Definitions
This area of OrderFlow allows an OrderFlow user to configure entire external APIs without code changes. This allows the specifics of external interfaces to be kept separate from OrderFlow's internal processes and logic. For example, a process to fetch a product catalogue from a remote system may consist of one API request, or it may consist of several requests and responses. OrderFlow's API configurations keep this detail separate from its core processing.
It also gives a high degree of power and flexibility to change how OrderFlow interacts with remote systems 'on the fly'. An example of this would be if a particular API to 'pull' orders from a remote shopping cart system was configured, and the remote system changed its status codes, then those changes could be reflected in OrderFlow immediately.
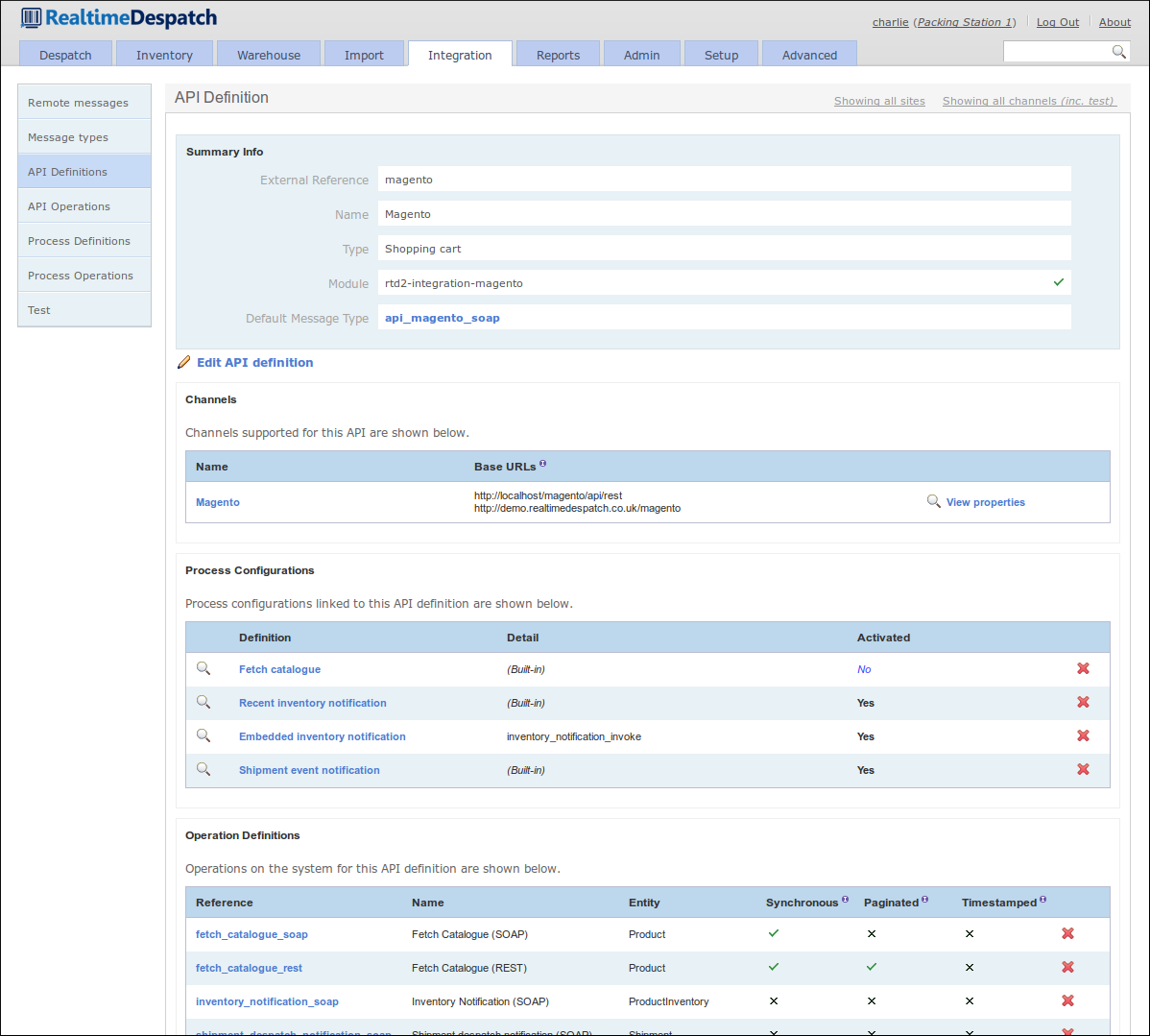
Process Definitions
OrderFlow's 'Process Framework' provides a powerful framework to control many of its internal processes, and to define and configure new ones.
The motivation behind this is to enable OrderFlow to be more dynamic in terms of being able to handle changing requirements without the need to develop, test, build and deploy new code. The framework allows logic to be encapsulated in scripts, reports, API operations and other constructs that control the process. Changing the processes has immediate effect.
For example, a process to re-fetch all failed orders might invoke a report to query which orders have failed to import successfully, then it might invoke an API operation to explicitly fetch details of those orders. Depending upon the scope of the process that is being run, a specific API will be invoked. This may be different for different scopes (e.g. sales channels).
Another example is a more simple 'shipment despatched notification' process.
This would be configured to invoke an API operation to notify a remote system
that a shipment has been despatched. The variation here would be in the API
operation - one or more remote messages may end up being sent in this case.
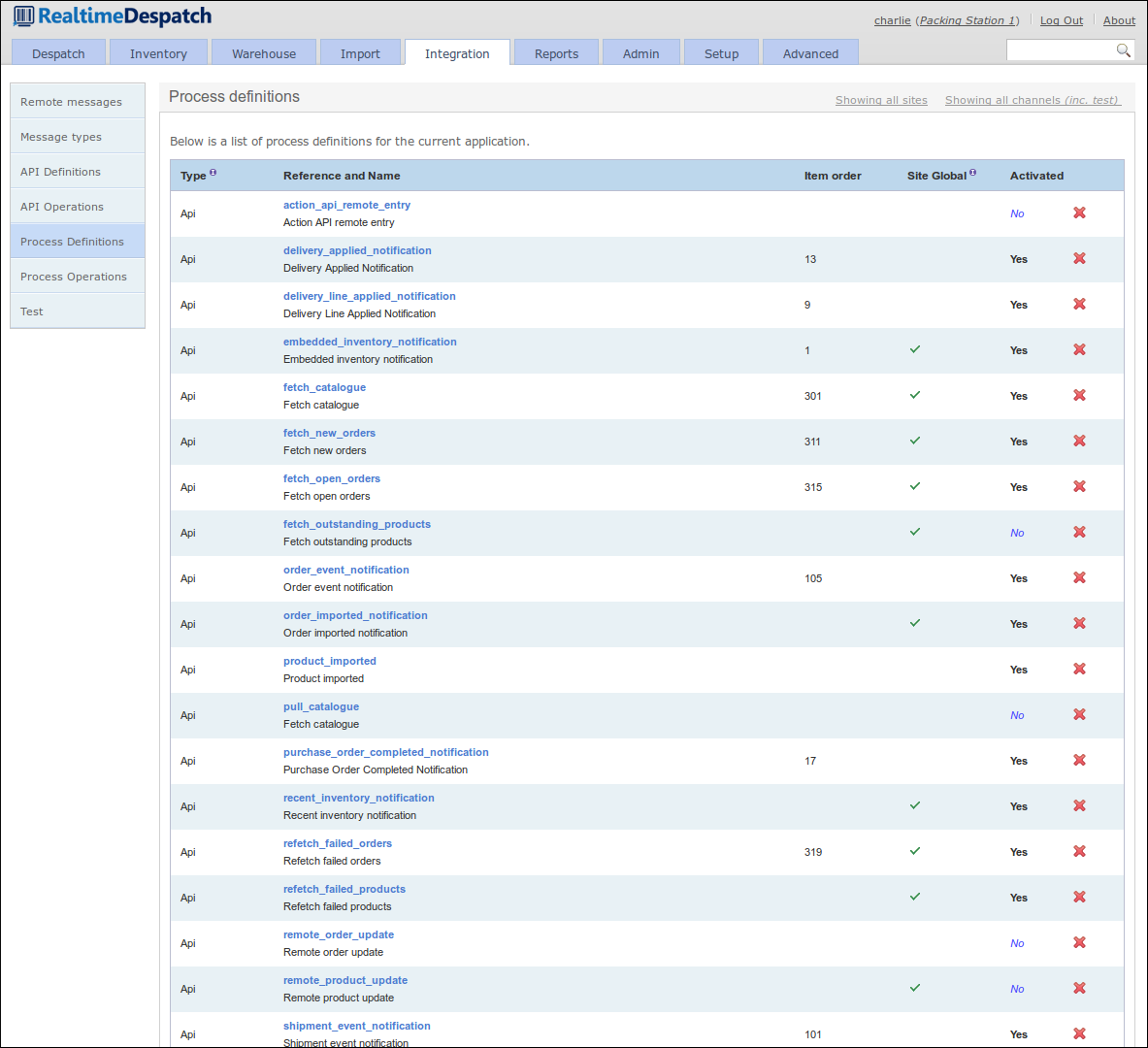
Reports
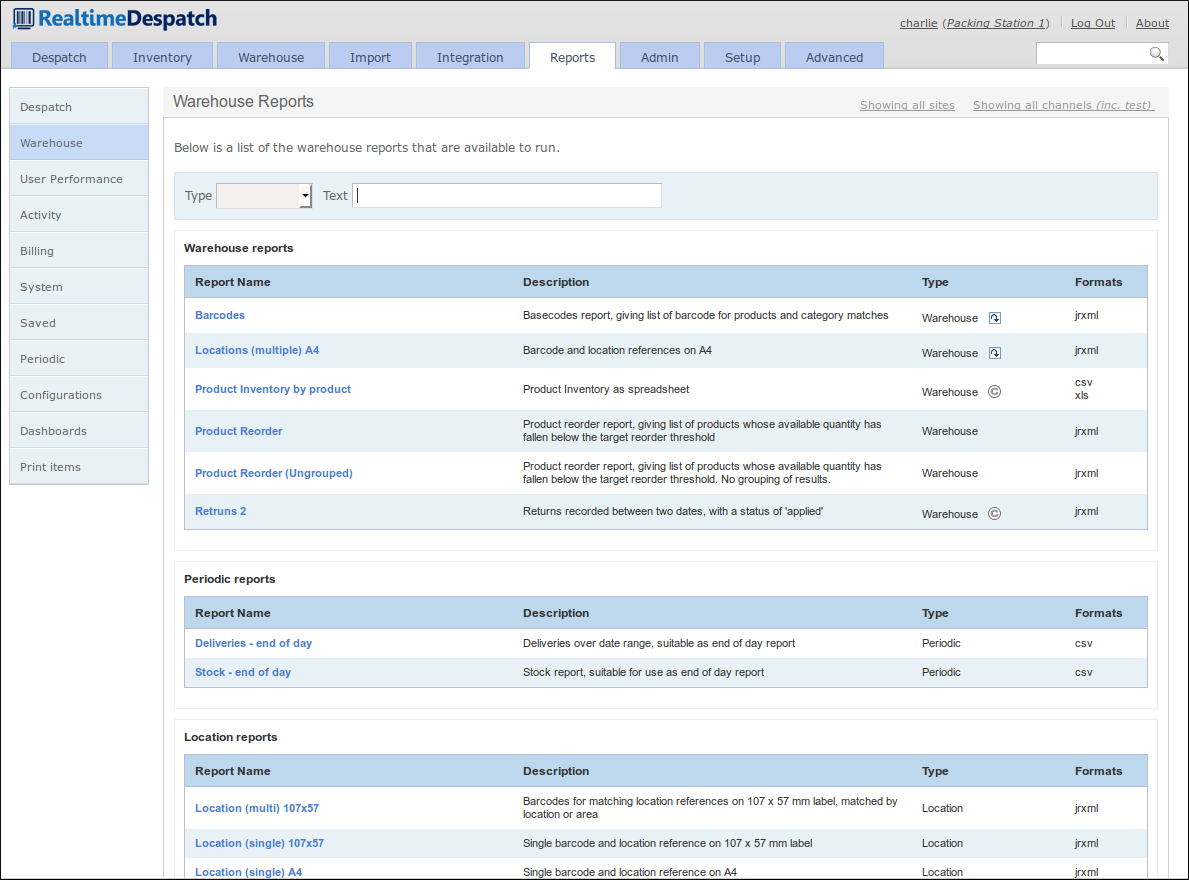
The Reports area of OrderFlow is where all the reports used by the system are configured. Some of them can also be run from the user interface, for display or download.
A 'report' is simply the extraction of data from OrderFlow's underlying database, presented in a particular format. Example formats could be comma-separated values (CSV), Excel spreadsheet (XLS), Portable Document Format (PDF), text or Jasper Reports XML format, which allows for more presentable output, e.g. despatch notes. More details on writing reports are available in the OrderFlow Report Writer's Guide.
Reports are used both externally, where the data is sent or downloaded to an external system, or internally to OrderFlow, for example to drive certain processes, or to present 'dashboard fragments' on the user interface.
The following screenshot shows some of the warehouse reports configured.
The Reports section also contains information on user activity and performance, plus billing configuration and metrics that third-party fulfilment houses can use to bill their clients.
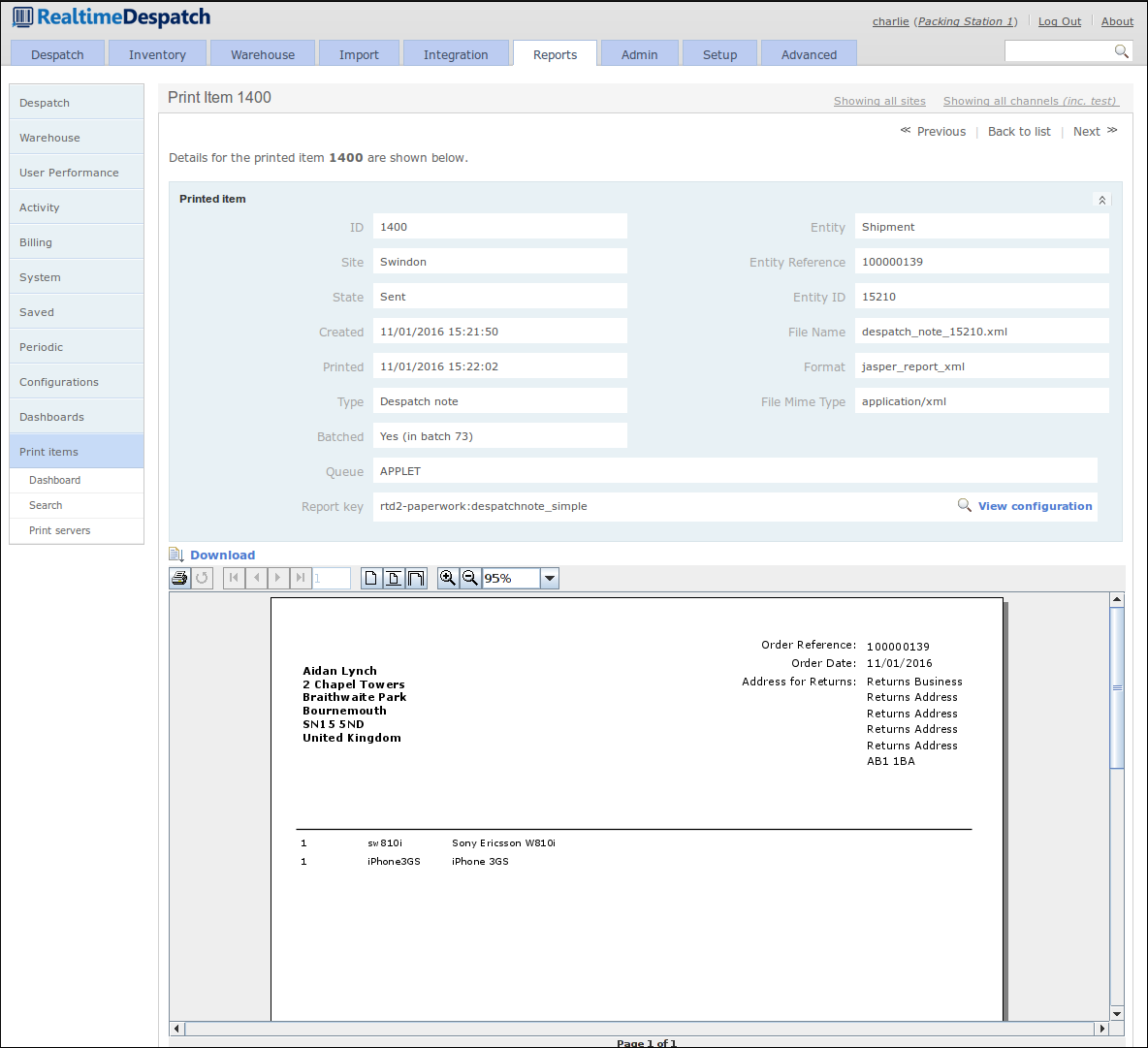
Finally, the Print Items sub-menu contains details of everything that OrderFlow has been requested to print, plus details of which print servers are connected. An example print item detail page is displayed below.
Admin
The Administration area of OrderFlow deals with the day-to-day running of the system, from the set-up of user permissions and role definitions, through logging and error management, to displaying which scheduled jobs are running and have run.
It is expected that the system manager would use this menu to keep abreast of any problems encountered in a running system.
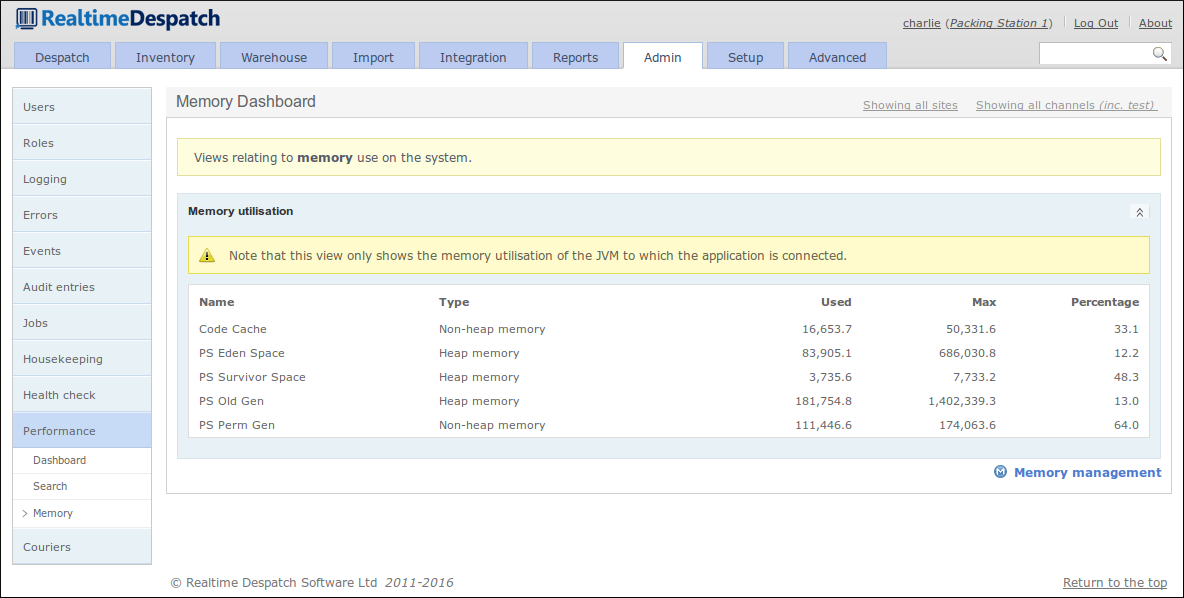
This area also shows system performance information and exposes configuration of the archiving and housekeeping operations within OrderFlow. These functions ensure that the system does not have to handle an ever-increasing amount of data, which would itself cause performance problems.
The following screenshot shows the Memory Dashboard, which details the memory utilisation of the OrderFlow instance's Java Virtual Machine (JVM).
Setup
The Setup area of OrderFlow is where the bulk of the configuration relating to business processes is made. This configuration includes what organisations, channels and sites are defined and active in the OrderFlow instance. It also includes all the configurable properties in the system, which are instrumental in controlling how OrderFlow behaves.
There are also sub-menus to configure couriers, batch types, print queues, workstations and other entities. More details are given in the following sections.
Sites, Organisations and Channels
As specified in the Order Processing section, OrderFlow can handle orders from multiple organisations, and multiple sales channels within organisations. It is also a multi-site system, supporting fulfilment of orders across multiple warehouses.
Whereas the relationship between organisations and channels is an inclusive one, OrderFlow considers sites to be orthogonal to these, i.e. it is possible for a shipment for a particular channel to be fulfilled in any site.
All these entities can be configured under the Channels, Organisations and Sites menus. The following screenshot shows an organisation detail page.
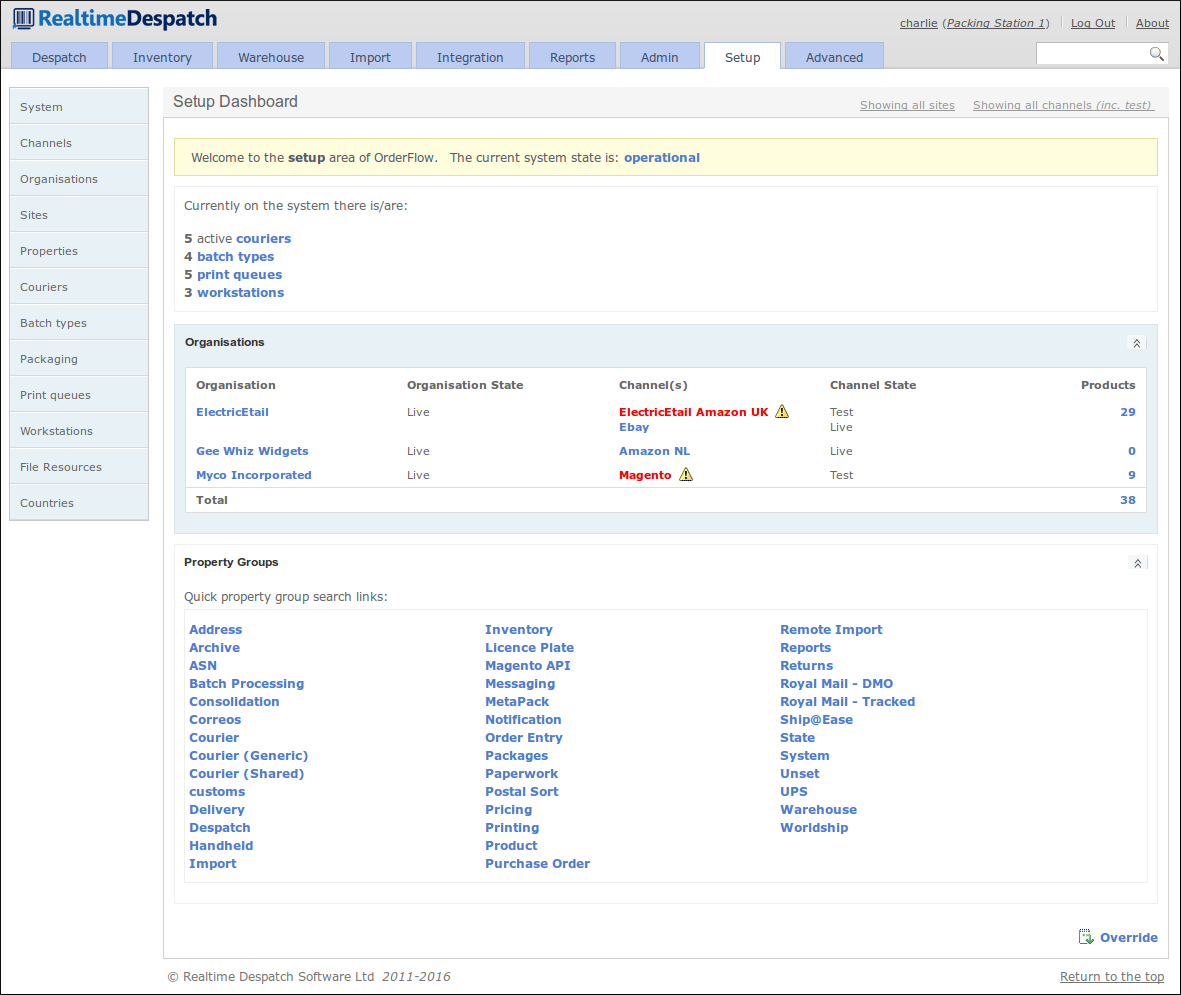
Application Properties
Application Properties within OrderFlow enable multi-layered configuration to be applied dynamically to a deployed instance. Typically, when the value of an application property is updated, that will have an immediate effect on the application, without needing to restart it.
Properties can control all sorts of aspects of OrderFlow, from despatch processing, through printing, to external system configuration and much more.
One very powerful aspect of application properties within OrderFlow is that they can be scoped and site-specific. This means that there can be several property values for a single property definition. The values would apply to different scopes (i.e. channels/organisations) or sites, thus allowing system behaviour to differ, depending upon the scope of the processing concerned, and to what site it is applicable.
For example, a shipment might have its courier assigned by a 'courier selection script' property. This property could have different values for different warehouses, because only certain couriers actually pick up from each warehouse. It may also differ based on the shipment's organisation (i.e. the company selling the goods). This would usually be the case, as it is typical that it is organisations who set up the contracts with courier companies. Finally, the script may also differ at the channel level, because only certain channels may attract certain courier services or options (e.g. eBay orders may be prevented from being despatched on a next day service).
The following screenshot shows a scriptable property with different scopes.
Couriers
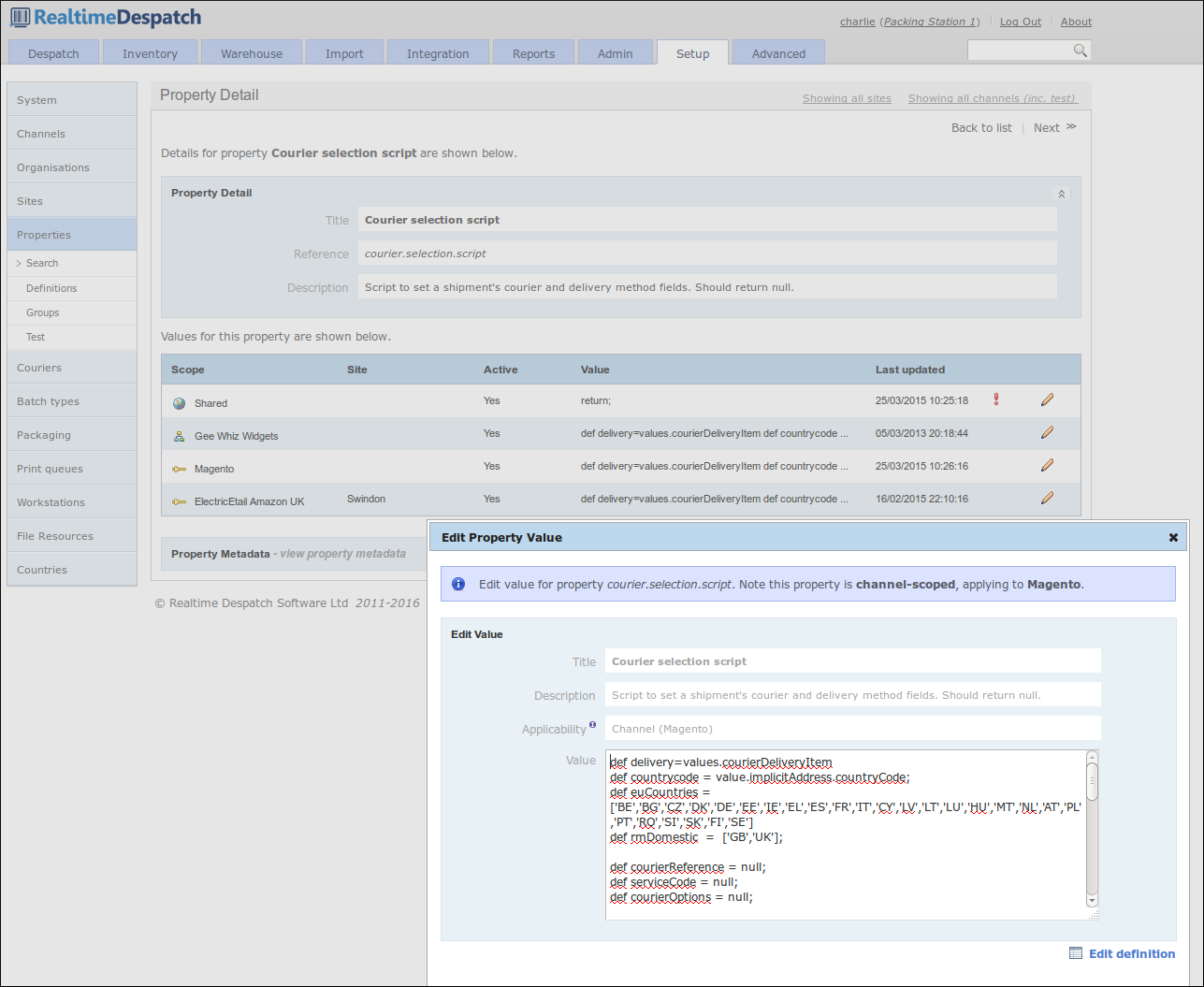
Couriers are integral to OrderFlow - shipments will not go anywhere unless despatched via a courier. Under the Couriers tab, OrderFlow exposes configuration that allows couriers of many different types to be set up.
The configuration required for couriers can range from simple to complex; from a simple 'printed postage impression' (PPI) courier, that just requires a label to be printed for a shipment, to a fully-integrated, real-time label-producing courier that has an up-to-date picture of the shipments it needs to collect at each scheduled pick-up.
Couriers can be configured to require despatch references, which can be managed by OrderFlow, or by the courier's own external system. A courier's external system can be remotely-accessible as a web service, for example, or it could be locally-installed on a packing station. In this case, communication to the courier's desktop system is via a print server instance.
Naturally within OrderFlow, couriers can be restricted to be applicable to only certain sites and certain channels and/or organisations (via a script).
A courier can also be configured to have many services (e.g. 'next day', '3-day' etc.) and options (e.g. 'signed for'), to which shipments within OrderFlow can be automatically assigned.
The following screenshot shows an example courier configuration.
Batch Types
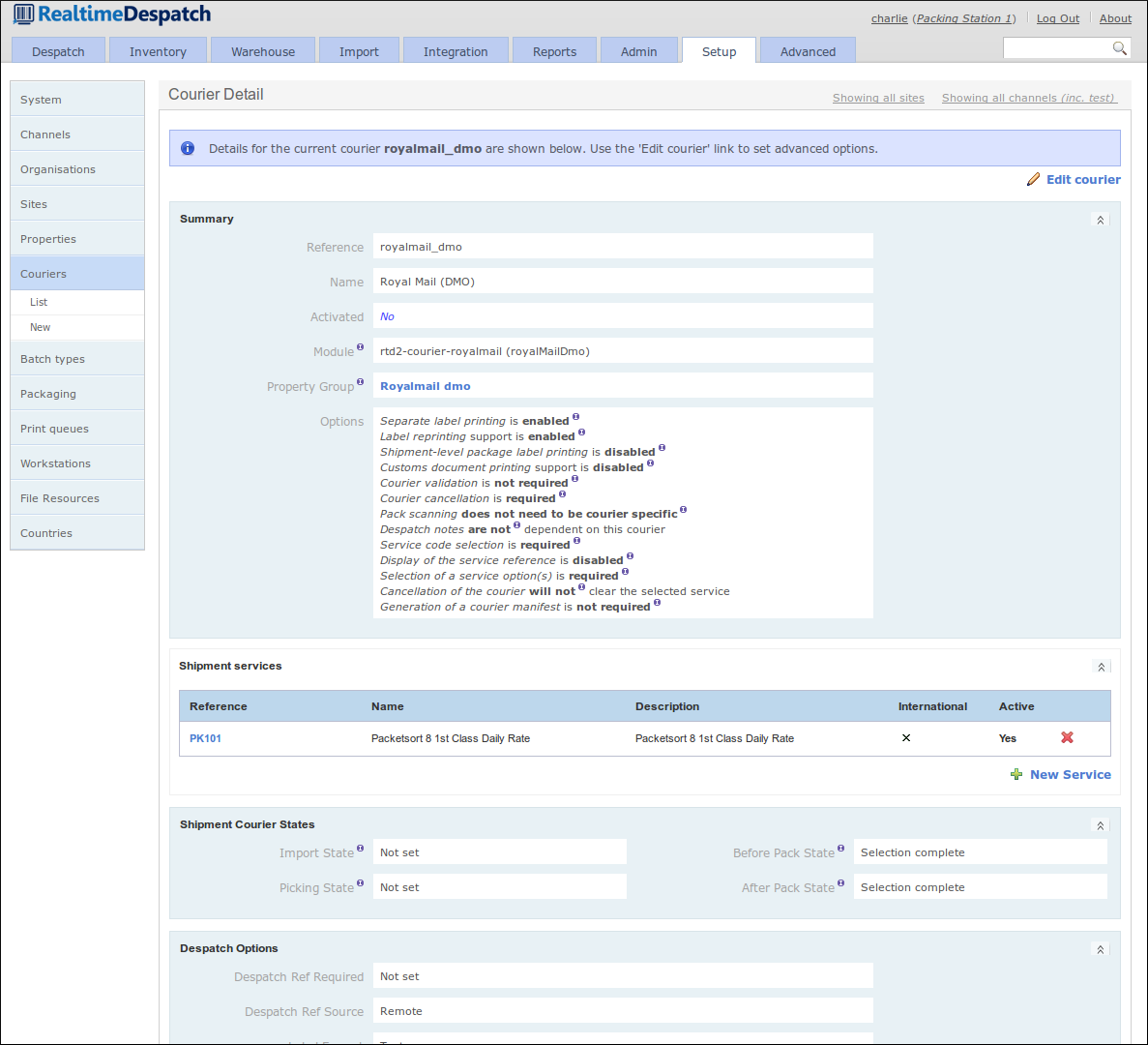
Shipment Batches (or just plain 'Batches') are defined in OrderFlow as groupings of shipments that it makes sense to process at the same time. By 'process', this typically means pick and pack. For example, high priority shipments might need to be processed separately before other standard priority shipments. Or shipments destined for a particular courier pick-up may need to be processed before other shipments destined for a later pick-up.
Like many things in OrderFlow, the behaviour of batches can be controlled by configuration, allowing warehouse processes to be changed without recourse to developing and deploying new code. This configuration is held in Batch Types, which allow aspects such as minimum and maximum batch size, sorting, picking type, packing type etc. to be set.
More information on batch types can be found in the Warehouse Processes Guide.
The following screenshot shows some of the configurable aspects of a batch type.
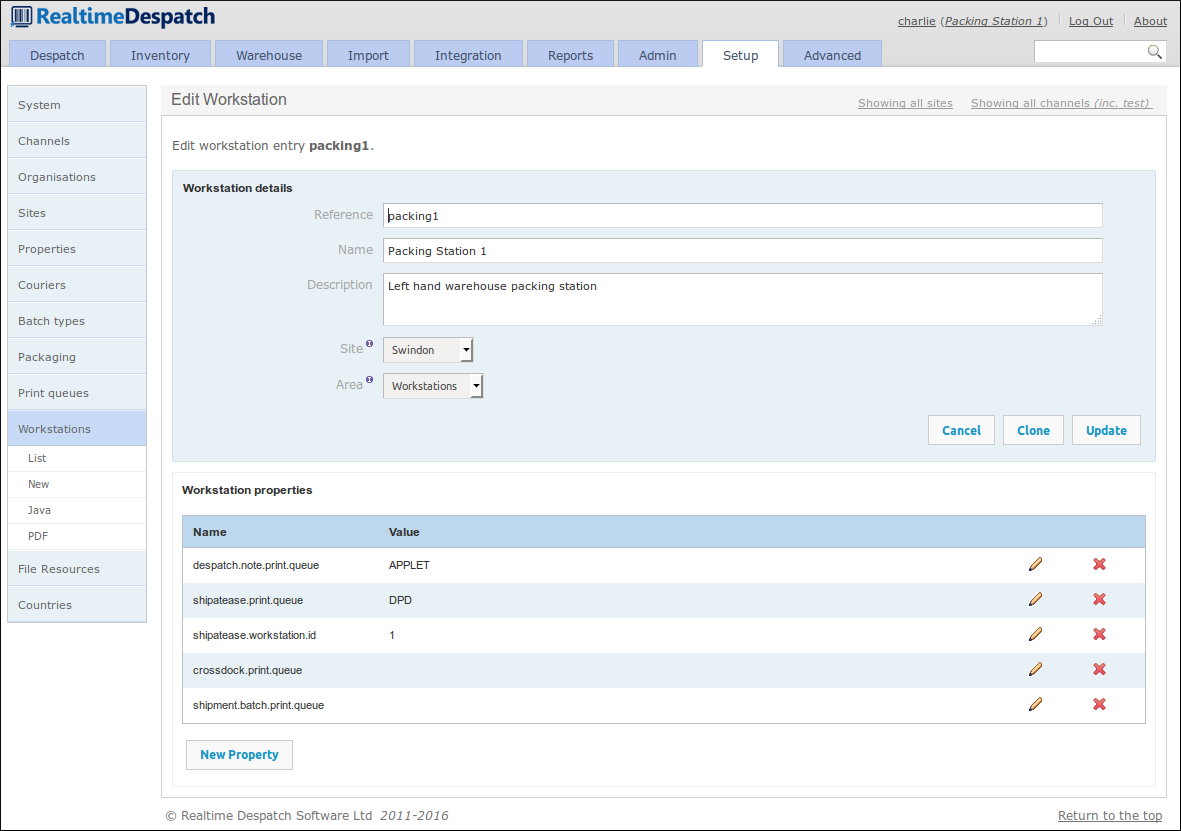
Workstations and Print Queues
The set-up of different Workstations in OrderFlow effectively allows it to communicate locally when accessed from a particular workstation. For example, configuring a workstation-specific print queue name allows OrderFlow to route print jobs to that queue, and only the print server on that workstation will be configured to poll that queue. The result is that print jobs will be printed on the printer attached to that workstation.
Print queues are used to route different kinds of 'printable' items to the correct place. This is typically a physical printer, but could also be a file system location, for example, when communicating with courier desktop systems. A separate application, called the Print Server, polls print queues to perform the actual printing.
Other Setup Configuration
There are other elements available to configure under the 'Setup' tab, that have not already been covered.
Packaging Types can be defined, which can be assigned to shipments during the despatch process to record how a shipment was packaged. This is useful for some organisations that want to report on how much packaging they use, to make it easier to order supplies.
It is also possible to define file resources in OrderFlow. These are images, documents or message bundles that can be used in various places in the system. For example, images are used on despatch notes, documents may back product datasheets, and message bundles can assist in producing internationalised paperwork from a single report definition.
Finally, the 'Setup' tab is where countries are configured. These are used in despatch operations to determine country-specific properties, usually when communicating with courier systems. For example, one courier may require the ISO 3166-1 alpha-2 (two-letter) code, whereas another may require the ISO 3166-1 numeric code. Both properties can be attached to the country object, making lookup easier.
Advanced
The Advanced section of OrderFlow is where the more advanced configuration is set. This configuration controls the fundamental behaviour of the application, and as such should only be changed by experienced system administrators or those with special knowledge or training in this area.
The advanced configuration covers the behaviour of data imports, which define how various data is imported onto OrderFlow. It defines the various states that entities on the system can pass through, and the operations that move them between states.
It includes configuration for events and their listeners, schedules and their handlers, and also when certain links are displayable. In addition to some advanced warehouse configuration, there is the possibility to change certain system features, such as menus, or even which software modules are loaded.
This section provides an overview of the advanced features of OrderFlow in more detail.
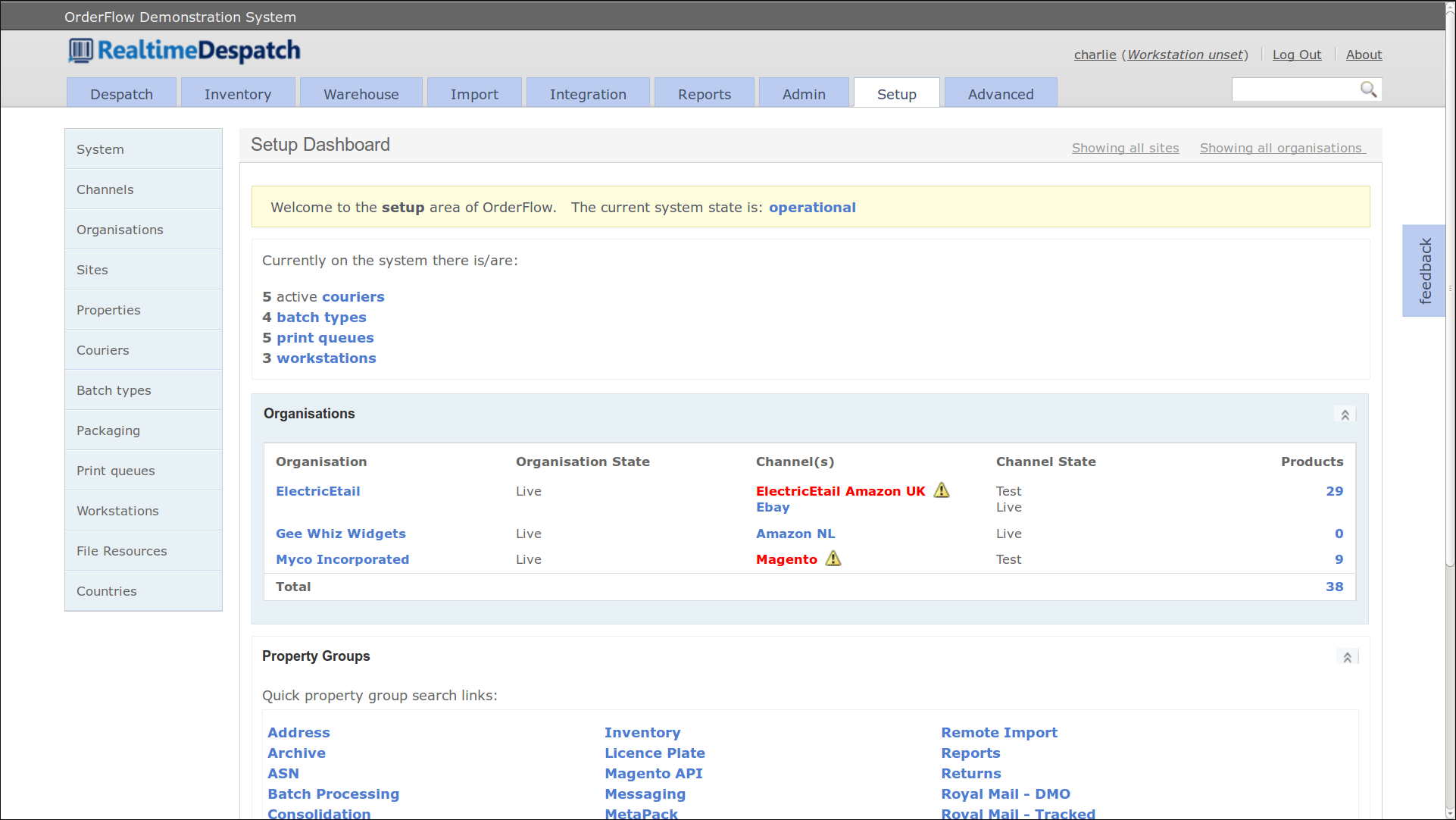
Import Configuration
Data can be imported into OrderFlow using a variety of mechanisms. The most simple is via OrderFlow's API, an XML over HTTP interface.
Alternatively, data files can be placed on file system locations accessible to OrderFlow, which in this case would periodically poll those directories and read the files. The configuration to define these locations, and how the files should be read and processed, is held under the Import Files sub-menu.
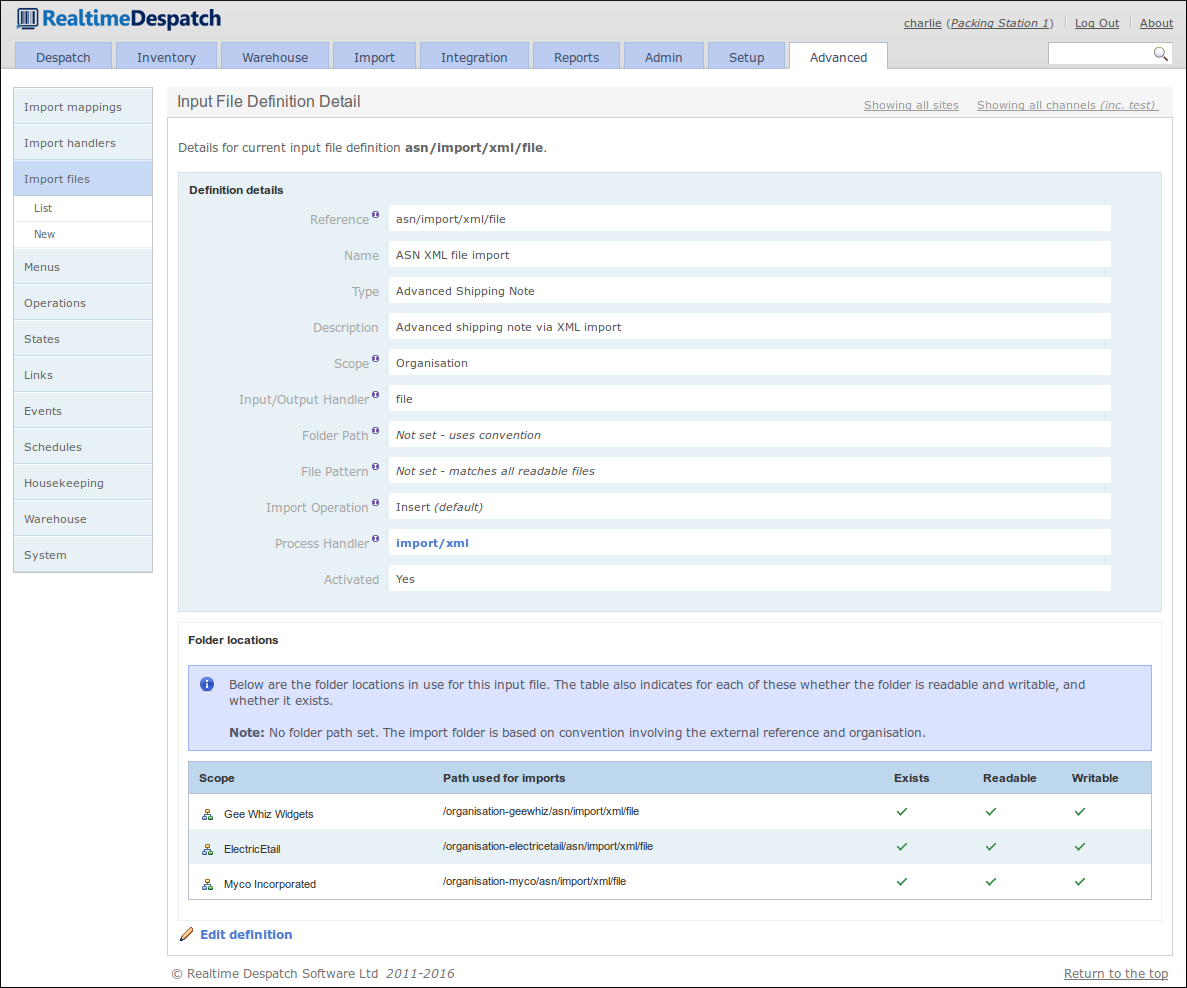
To define how a file should be processed, the Import File definitions
reference Import Handler definitions. These reference specific functions
within OrderFlow that define how the data is processed. They also define the
expected object type, the format and any encoding that the data has.
Additionally, a data transformation can be applied at this stage, to potentially
label the imported data fields to expected values.
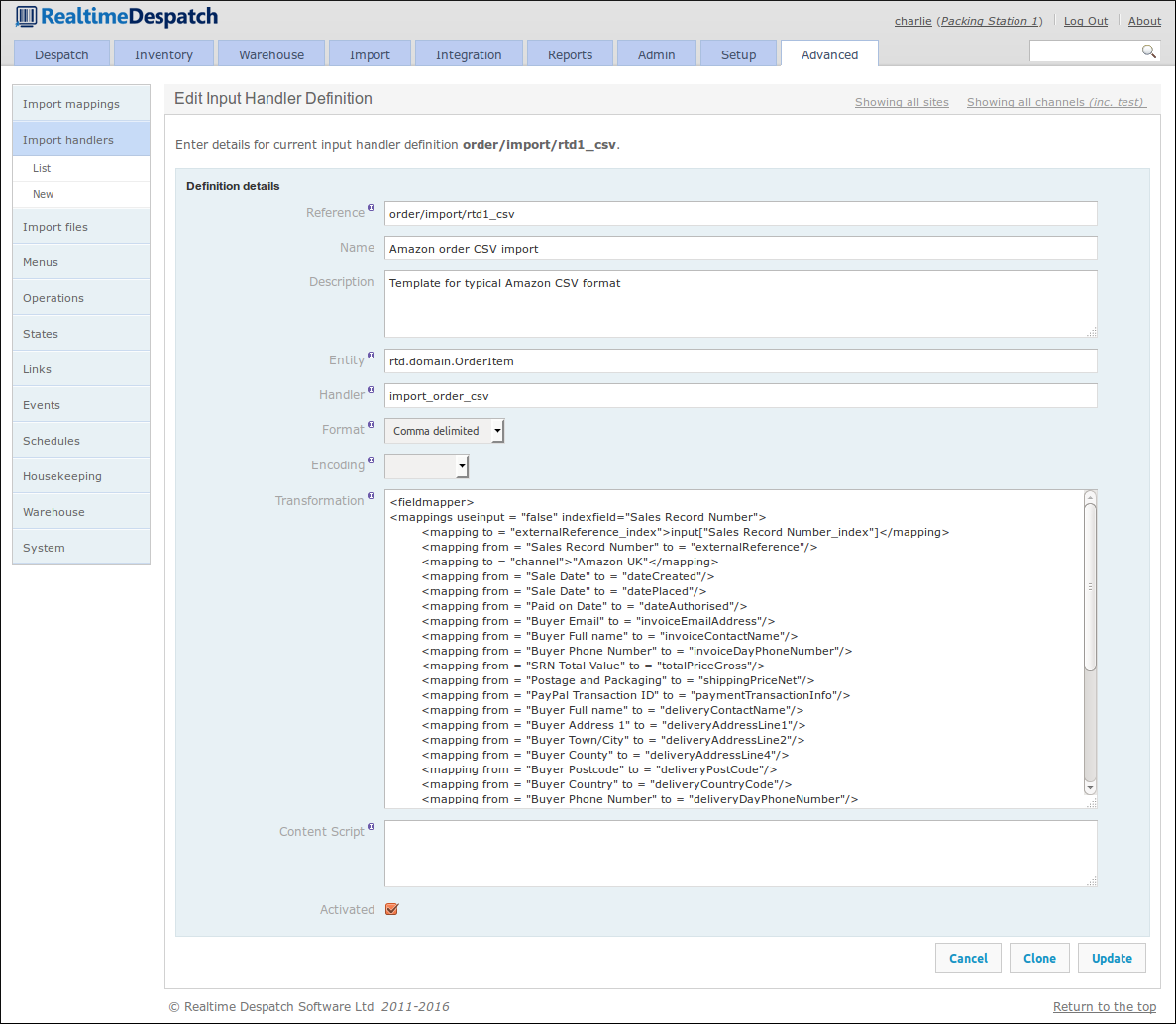
Finally, to ensure that imported data can be further transformed through configuration, each imported data object is passed through an Import Mapping. This is the case for data imported from file, or via the API.
Import Mappings can be defined for an object and scoped by channel, so that data received from different sales channels can be treated differently. These mappings contain a pre-translation script and a post-translation script - the difference between these is expanded upon in the Importing Guide. Each script can contain multiple mappings that utilise the Groovy scripting language, to apply logic and potentially transform individual data fields in the imported data. Additionally, the post-translation script can utilise functionality in OrderFlow to apply more logic or further change the imported entities.
An example of what import mappings can do is the following order import mapping configured for the 'Magento' sales channel. The pre-translation sets a few attributes of the order and shipment, and applies some logic when setting the mobile phone number. The post-translation invokes pre-defined functionality that sets the weight, courier and batch type of the shipment.
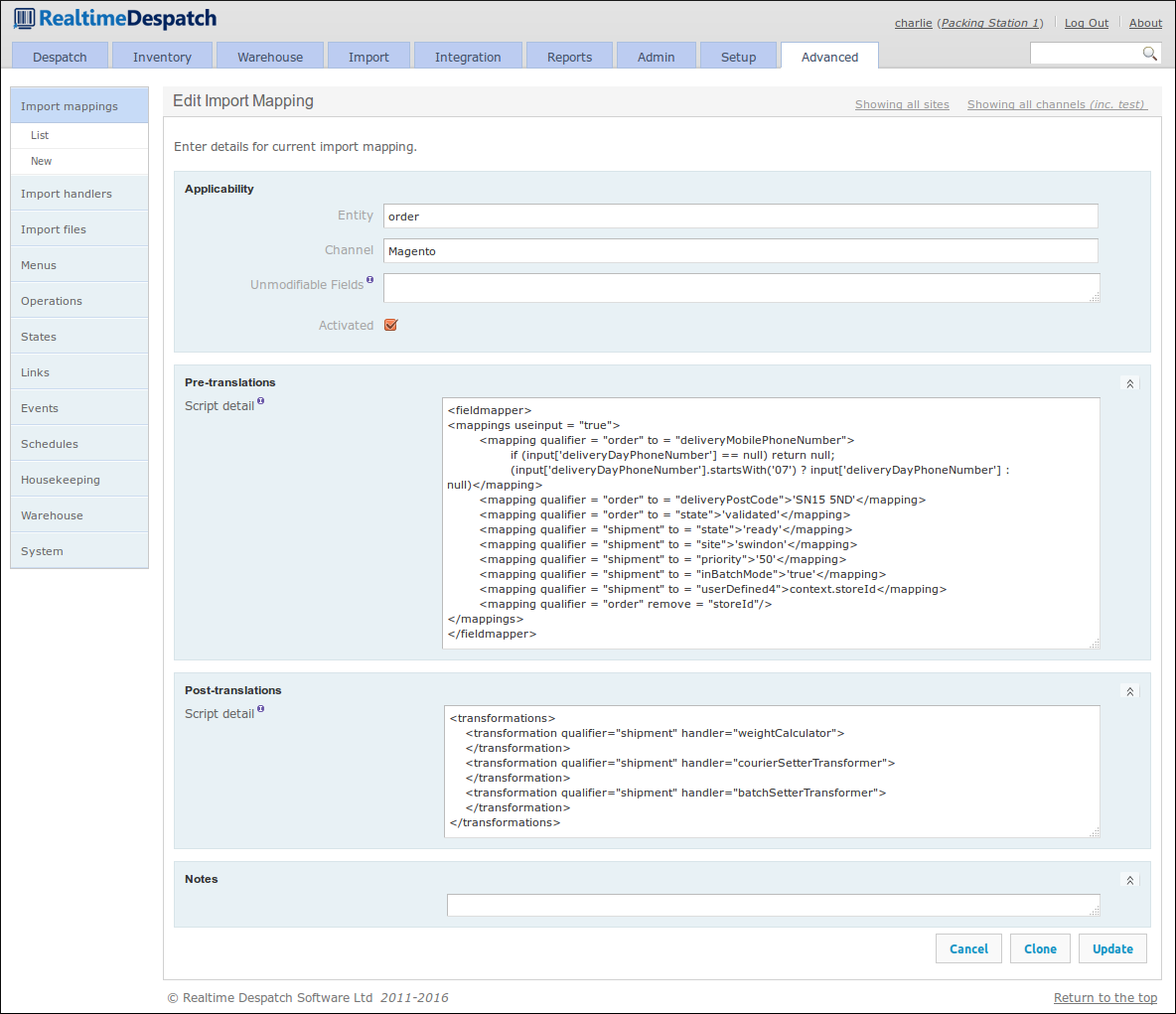
Menus
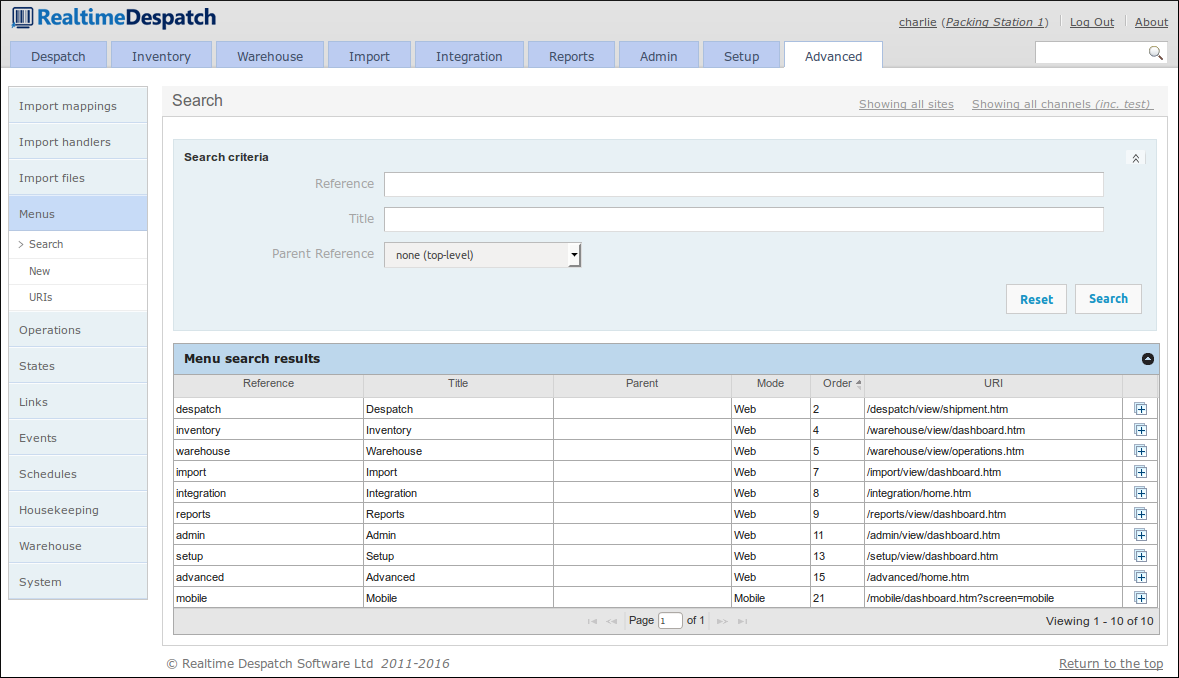
The menus defined on the desktop, handheld and mobile interfaces are all defined in the Menus sub-menu of the Advanced tab on the desktop interface.
Each menu entry has a 'mode', which defines which of OrderFlow's interfaces it appears on. Each menu entry will define a URI, which is the (relative) URI that will be accessed when the menu is selected. Menu hierarchy is derived from each menu entry's parent menu - the top-level menus can be seen in the following screenshot.
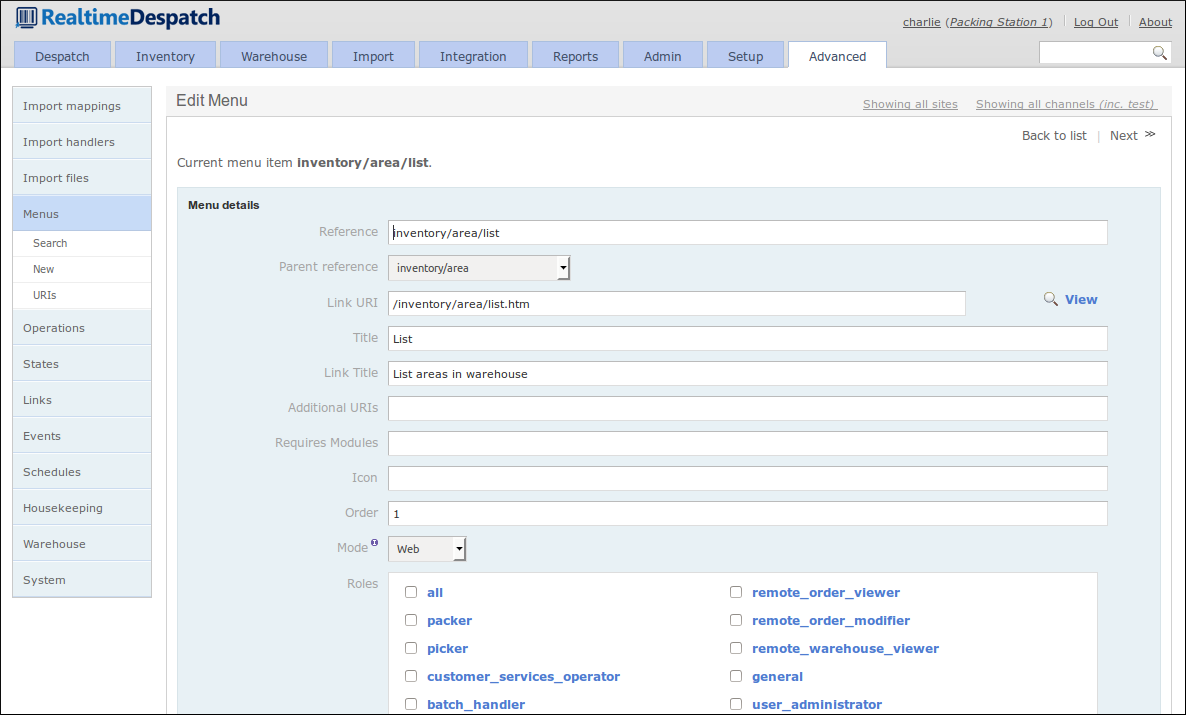
Menu entities themselves can be role-restricted; that is, they will only be displayed to users that have certain roles. This makes the OrderFlow interface appear different to different users - something that is quite useful as it can be used to restrict more advanced features to certain users. For example, warehouse staff whose role it is to pack shipments do not need access to the Advanced tab.
States and Operations
One of OrderFlow's more powerful features is its configurable state transition model. This means that the processing of the main transactional entities (such as orders, shipments and order lines) can be changed 'on the fly' in a deployed system, just by changing the configuration.
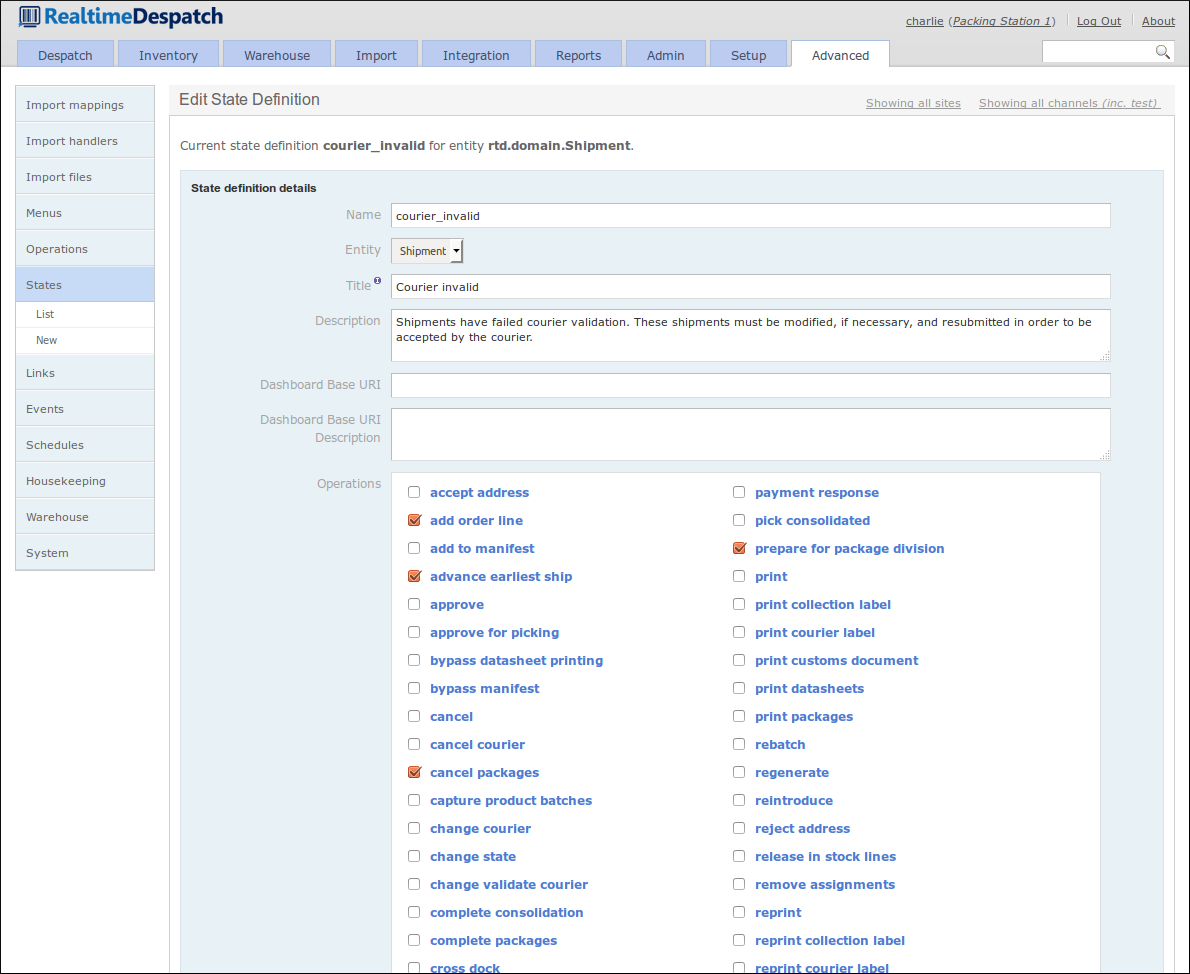
States are defined for orders, shipments and order lines. Each state definition references the operations that are available to an object while in that state. For example, a shipment in the pending approval state only has the 'approve' and 'defer approval' operations available to it.
The following screenshot shows part of the 'Courier invalid' state definition for the shipment object.
Each operation referenced by a state definition defines what functionality is invoked when that operation is invoked. It does this by referencing known functionality via the handler attribute.
When an operation is invoked, the object is typically assigned a new state. The exact state to be assigned is based on fall-back logic that uses the invoked functionality and the operation definition, which can contain scripted logic. If an object has a parent object (e.g. a shipment's parent object is an order), then the parent object's state can be defined to be automatically updated if all its children have reached the operation's target state.
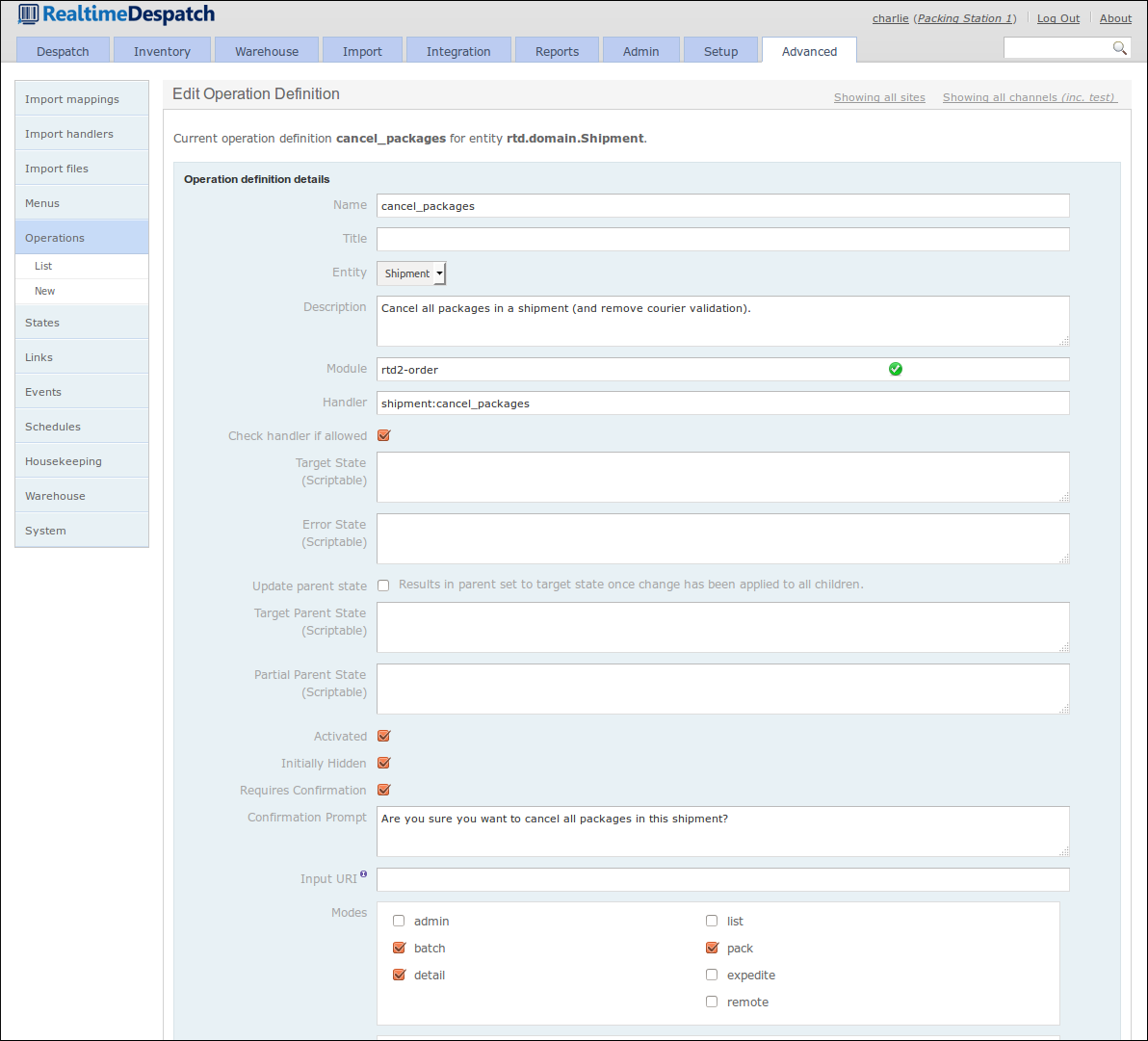
An operation definition can also be assigned modes, which determine where in the desktop user interface the operation will be made available. For example, operations with the mode 'detail' are presented to the user as buttons on the object detail pages.
Similarly to menus, operations can be restricted to certain roles, so that more advanced operations are not invokable by all users.
Links
A Link definition in OrderFlow is a configurable object that gives control over which links (i.e. hyperlinks or icon links) are displayed on the desktop user interface. Each link defines a URI to where it leads, if invoked.
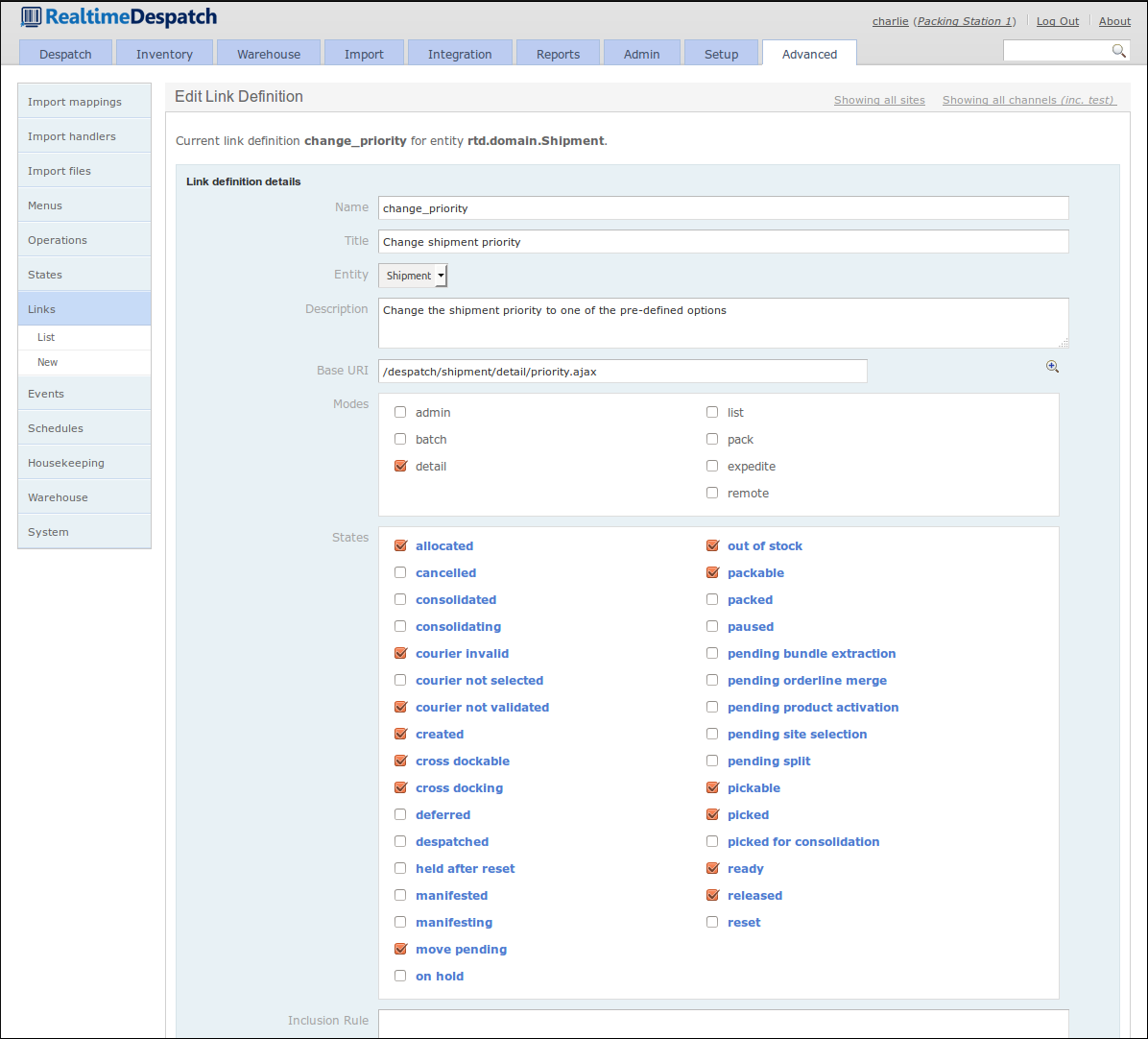
Each link definition applies to an object (e.g. shipment, order etc.), and defines the states in which the link should be displayed. Similarly to the operation definition, a link definition can also be assigned modes, which determine where in the desktop user interface the link will be made available.
The following screenshot shows a 'Change shipment priority' link definition for the shipment object.
Events
The Events section of OrderFlow is another area that adds to the power and flexibity of the system. As various changes to entities occur, OrderFlow can fire events, which contain details of what has just happened to the object concerned.
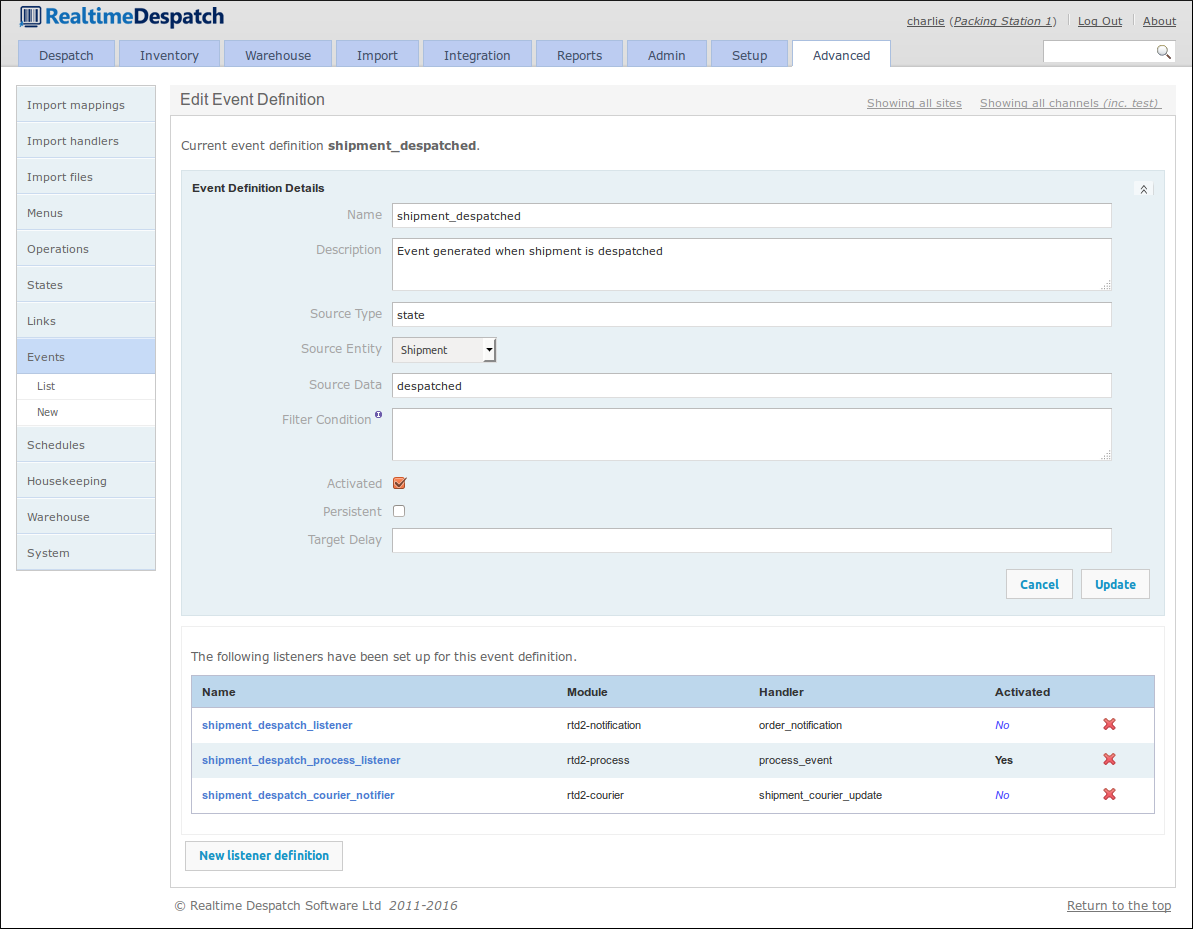
Event definitions and their listeners define what functionality should be invoked when certain events fire. For example, if a shipment has just been marked as despatched, a 'shipment despatched' event is fired, and the event definition for this event invokes each of the configured active listeners for this event. One of these listeners may ultimately notify an external system (e.g. a shopping cart) of this event.
An event definition can support a comma-separated list of sourceData values. This allows the associated event listeners to be fired for each of the values supplied. For example, if you want to fire the same event listener when a shipment is in the state packed and despatched, the value for sourceData would be packed,despatched.
The configurability of event definitions and their listeners allows system behaviour to be changed without needing to develop and deploy new code.
Schedules
In order that OrderFlow can present a real-time picture of warehouse activity in a performant manner, some of its processing needs to be done in the background, i.e. not in response to user or external system action. For example, it would soon fall over if it tried to calculate the overall picture of inventory levels following every single stock change.
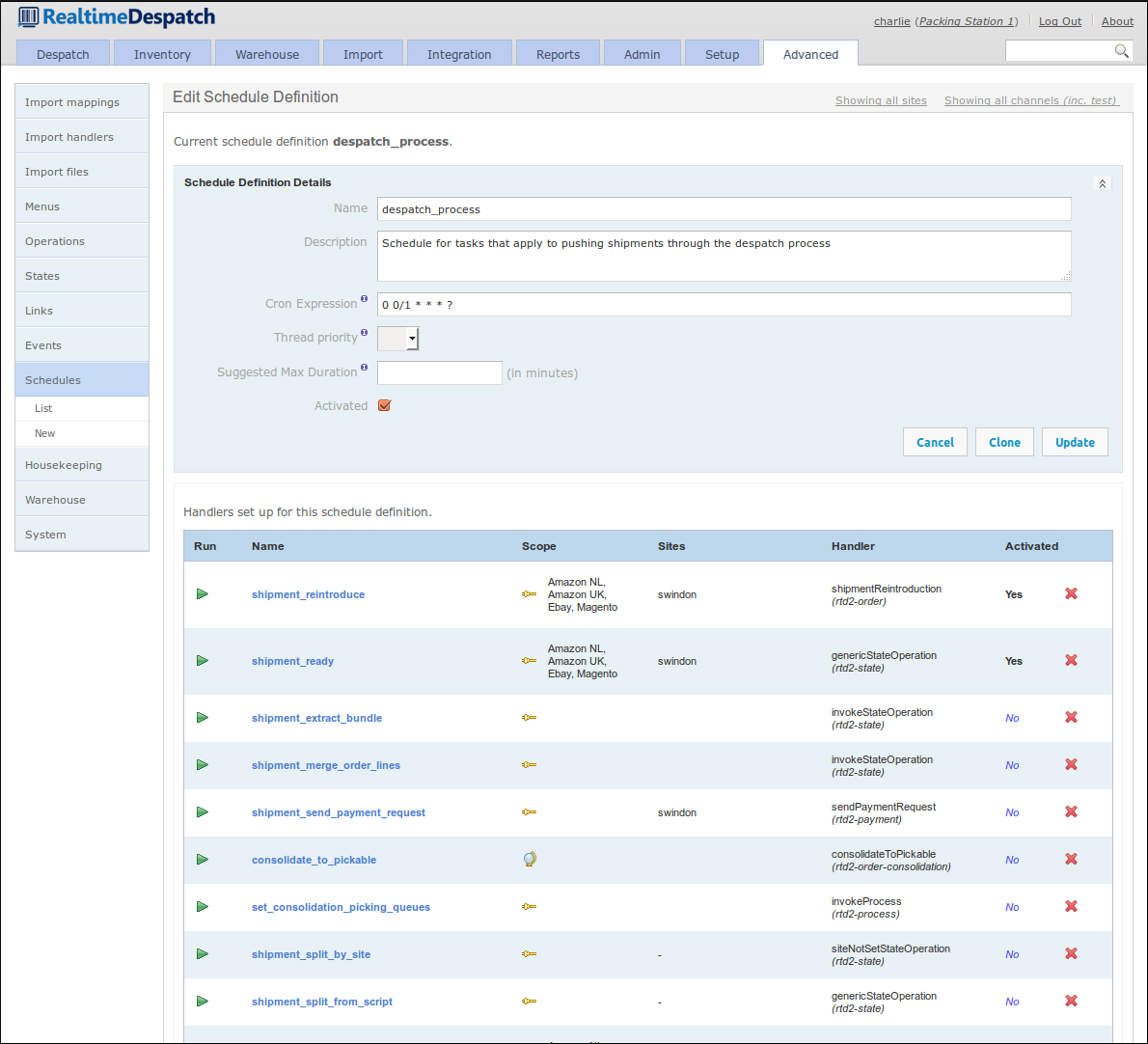
It is for this reason (amongst others) that OrderFlow has a scheduling capability, which allows for processes to run at predefined times throughout each day. This capability is configured in Schedule Definitions, which are each associated with a cron expression, to define when the schedule will fire.
Schedule Handlers can be attached to schedule definitions - these reference known functionality in OrderFlow, which will be executed in order when the schedule fires. Each handler can be restricted to certain sites, organisations and channels, if required, and each can be configured to pass certain parameters to the invoked functionality. Additionally, each handler invocation can be configured to repeat for a defined duration or count.
Schedule handler invocations can be recorded in the database for later inspection. This provides useful evidence of system behaviour, if necessary.
The following screenshot shows a schedule definition, which fires every minute and invokes the active handlers.
Warehouse Configuration
The advanced Warehouse section allows the configuration of various warehouse-related aspects of OrderFlow. This section gives an overview of some of these aspects.
Location and Product Types
Location Types and Product Types can be defined here; these enable a high degree of flexibility for organisations to set up the warehouse in the exact way that they want to, as these types essentially add a layer of abstraction in front of the attributes that a location or product may have. This allows subtly-different types to be defined, which will influence warehouse behaviour in respect to location and product usage.
The following screenshot shows the definition of a 'Incoming - preconsolidation' location type.
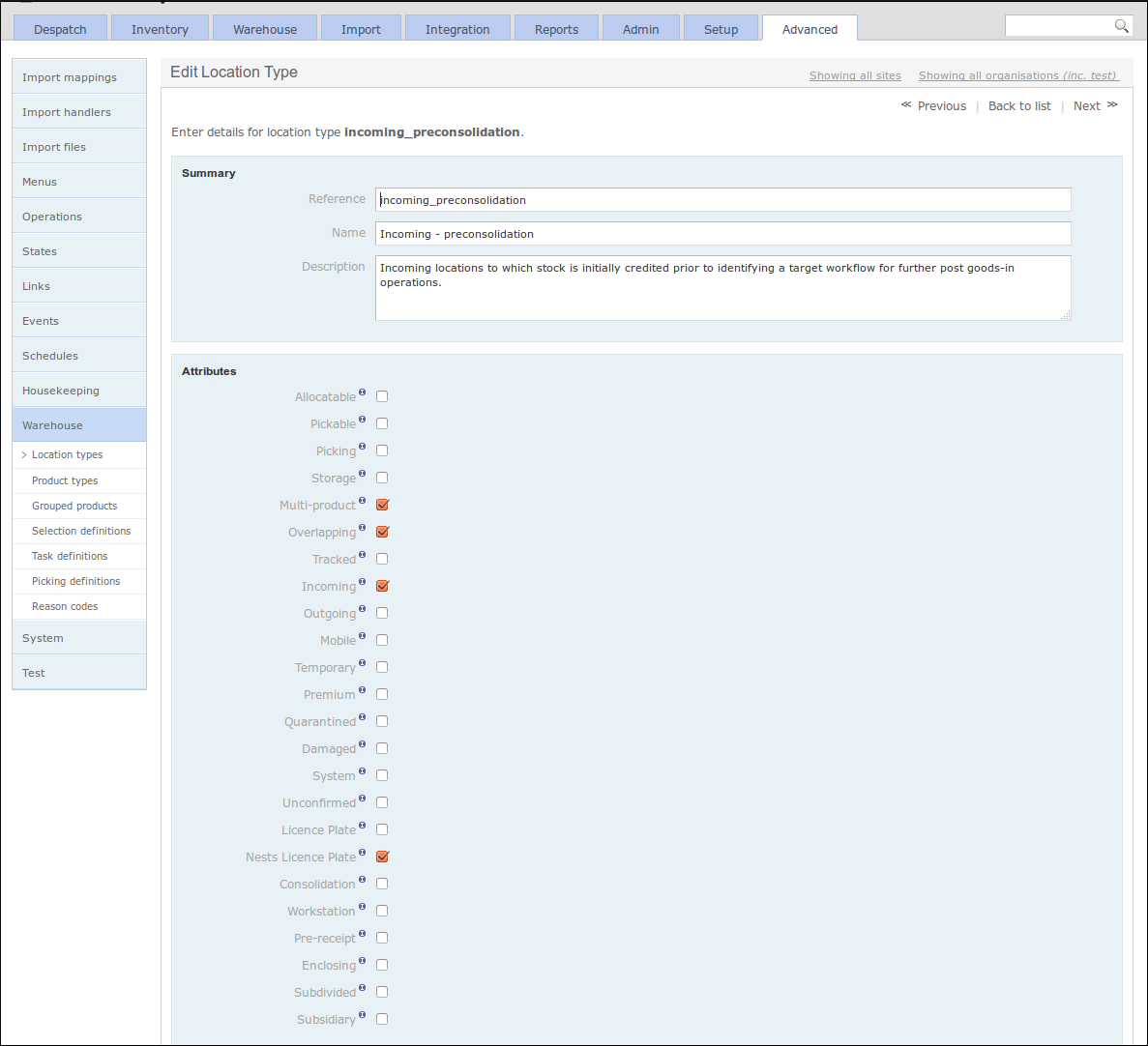
Location Selection Definitions
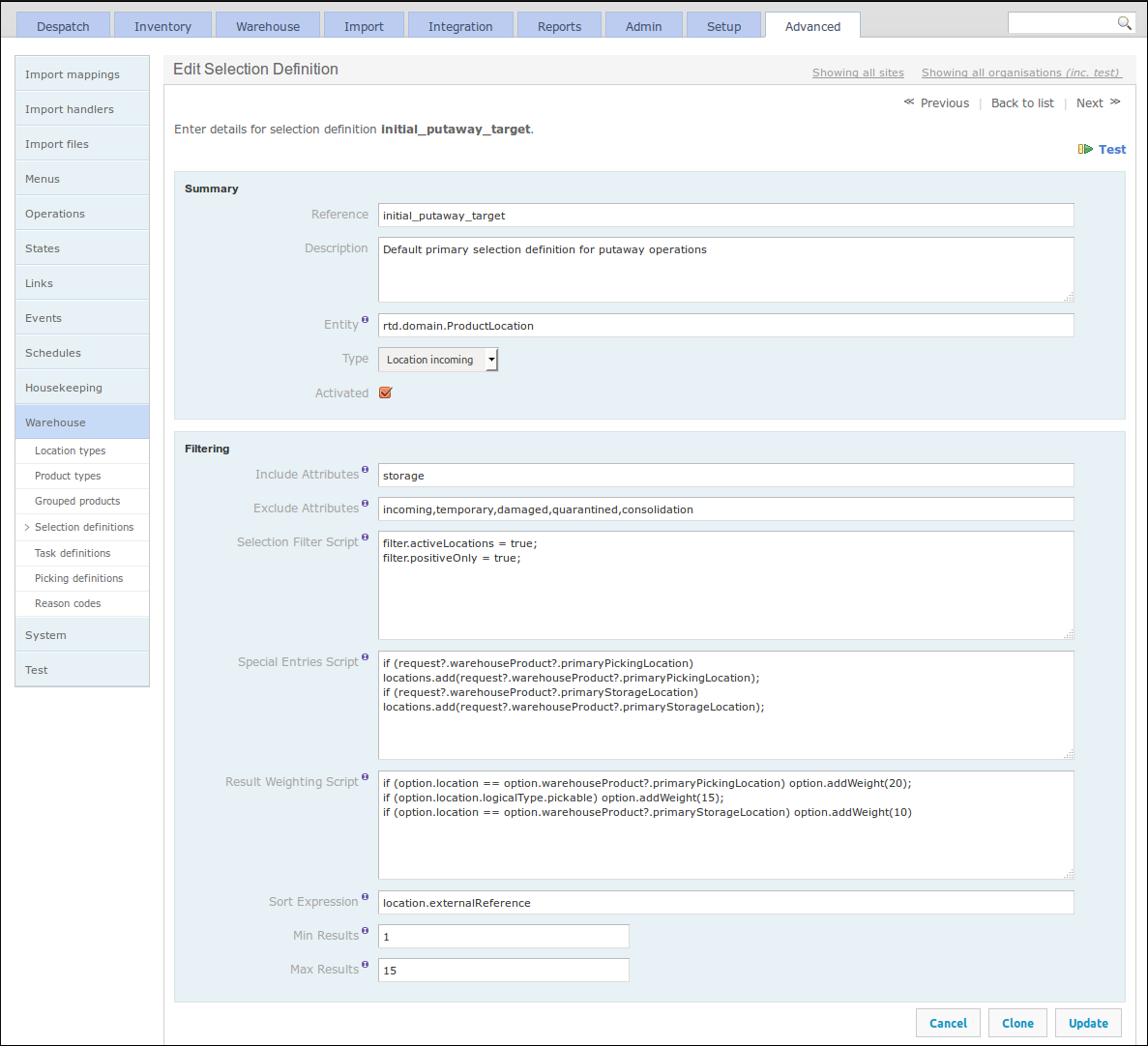
Location Selection Definitions (or just 'Selection Definitions') expose a mechanism to select warehouse locations for certain tasks, in a configurable manner. These selection definitions can then be used in various places in OrderFlow, and as such can be changed or adjusted if necessary, changing the behaviour of the application without the need for any code to be changed.
A selection definition can filter locations by their attributes, either by
inclusion or exclusion. It also has a filter script, which allows further
flexible configuration to be applied via hooks into the search objects.
Sorting, weighting and results sizes can be configured to give fine-grained
control over the location selection results.
The following screenshot shows an example of a location selection definition.
Task Definitions
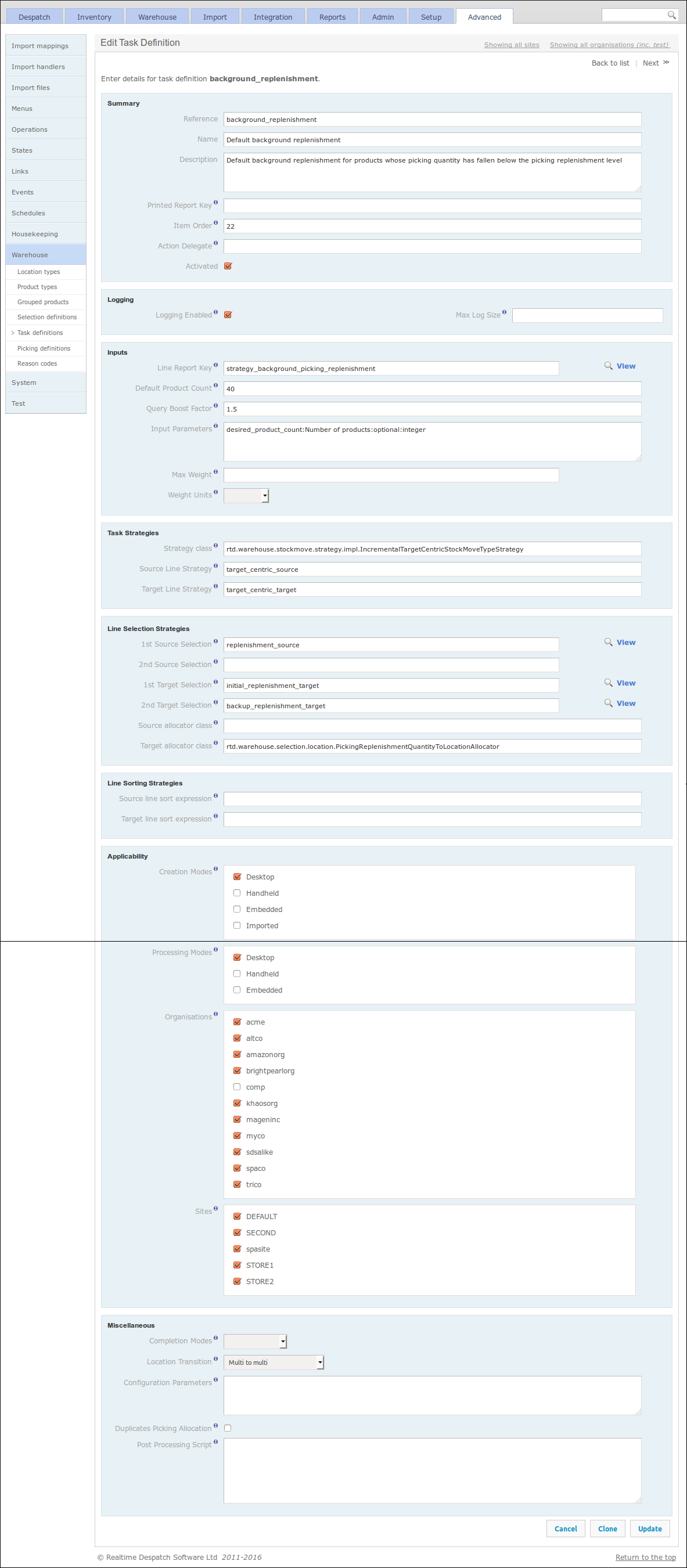
Stock move tasks, as introduced in the Stock Move Tasks section, are instructions to move stock from one location to another. To determine how much of which stock to move from which location to which other location, OrderFlow uses the configurable Task Definition object.
Such an object facilitates the automatic creation of the right stock move tasks at the right time. The task definition defines which built-in strategy will be used when creating tasks of this type. This strategy may utilise a report to determine which lines to include in the task, or it may use a configured line selection strategy, which references a Location Selection Definition (as detailed in the previous section).
Sorting, scoping and creation and processing modes can also be defined in a task definition, as well as other options. See the Warehouse Processes Guide for more information.
The following screenshot shows a task definition for the 'Default background replenishment' task.
Picking Definitions
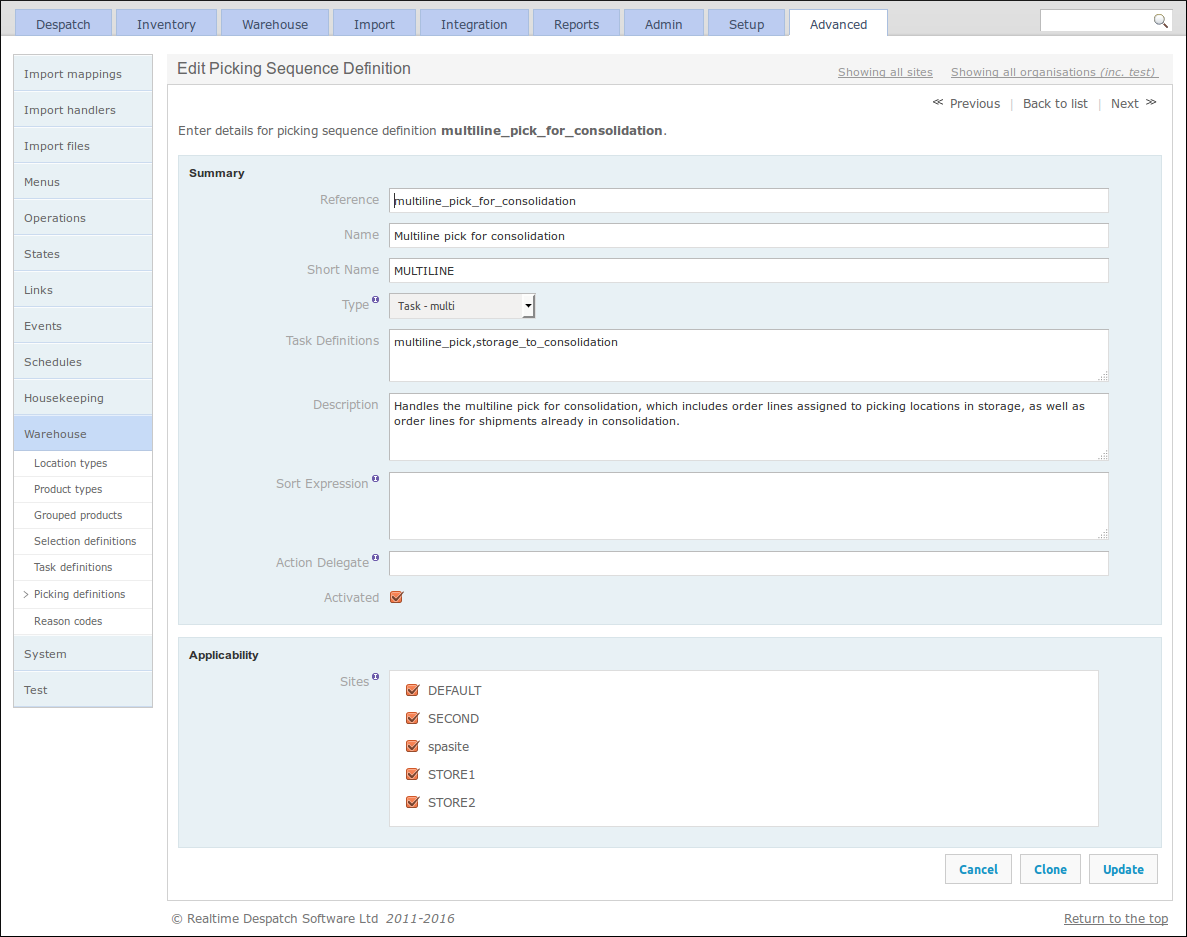
OrderFlow's Picking Sequence Definitions can also be configured under the Warehouse sub-menu. Picking Sequences are a mechanism to combine different task types into the same picking operation, to improve the efficiency of picking operations in the warehouse.
A picking sequence definition can be assigned a sort expression, and also hook into specific logic to be invoked when the picking sequence is complete. More details can be found in the Warehouse Processes Guide.
The following screenshot shows an example 'Multiline pick for consolidation' picking sequence definition, which combines the task definitions 'multiline pick' and 'storage to consolidation'.
Reason Codes
Finally, Warehouse Reason Codes can be configured under the Warehouse sub-menu. These provide a flexible way of controlling certain aspects of the warehouse process, such as what options are presented to users when making stock adjustments or setting return reasons. As the following screenshot shows, their applicability can be restricted by site and also restricted to certain handheld operations.
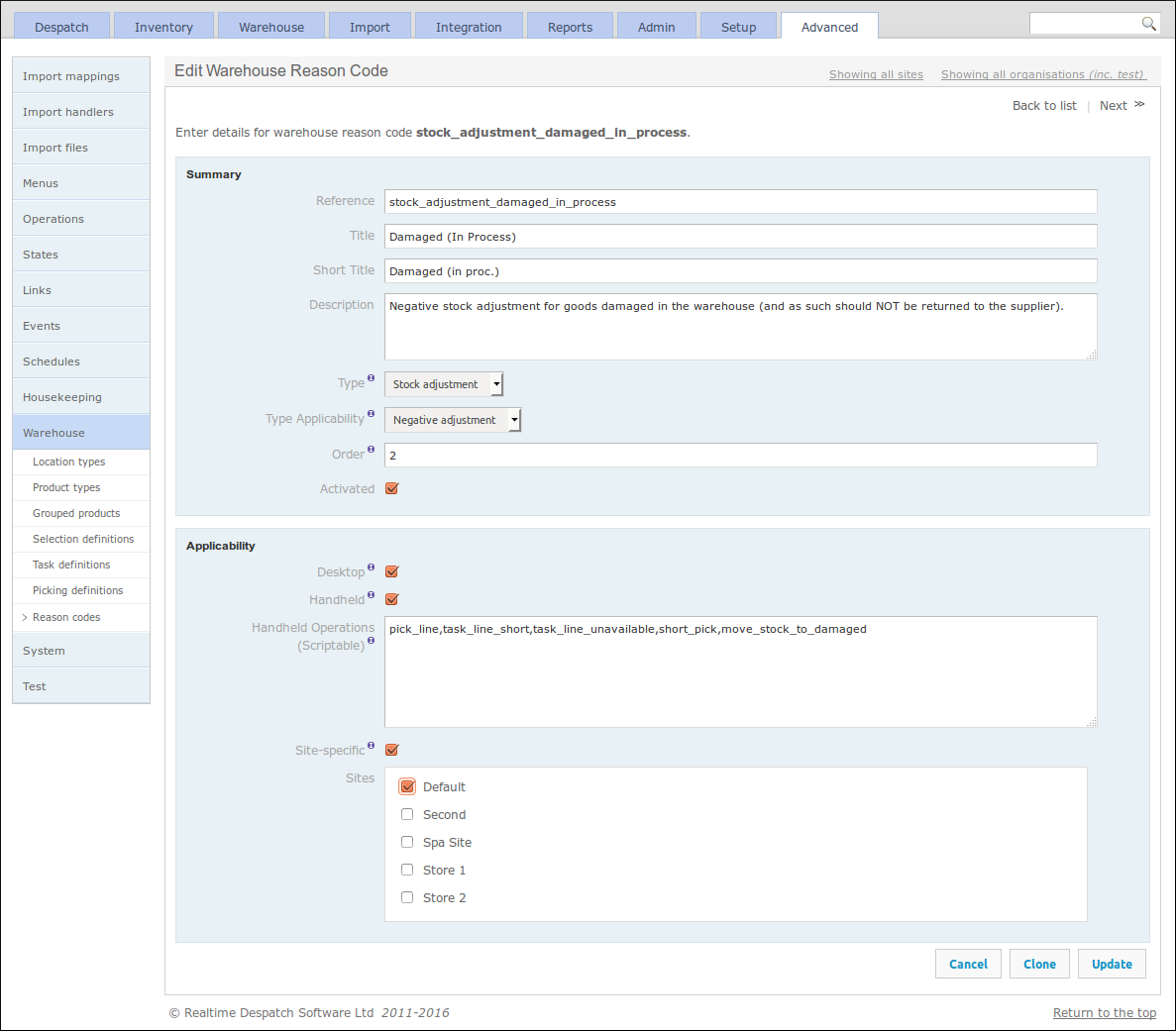
System, Housekeeping and Test
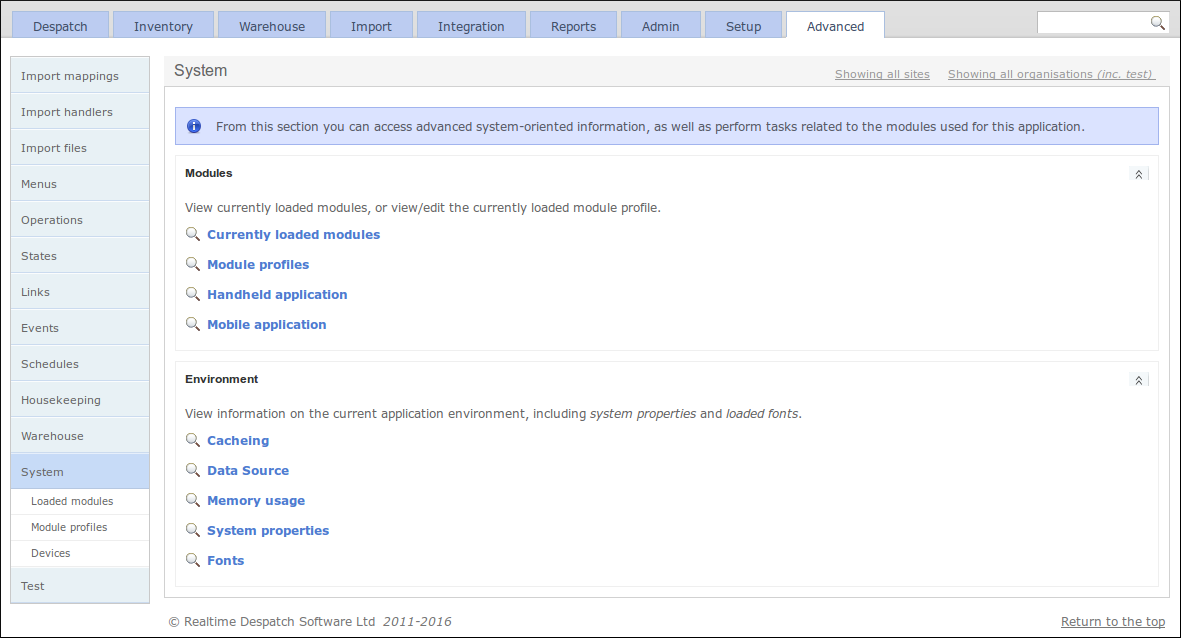
The Housekeeping area of OrderFlow contains configuration for dealing with purging and archiving of data from the system. Purging data allows non-critical event data to be permanently deleted from the system, whereas archiving allows business transactional data to be removed from the system, potentially to the file system or another database, for possible later business analysis.
The System sub-menu includes the configuration for which software modules are loaded on the currently-running instance. OrderFlow is a modular application, which means that, on top of a set of core modules, there are many optional modules that deliver specific functionality. The optional modules are enabled according to what functionality a customer requires. It is possible to change the module configuration, but only those modules that have been commissioned by Realtime Despatch can be enabled.
Additionally, this section includes the display of various system environment properties, memory usage and loaded fonts. It also provides some control over resetting the system cache and data source.
Finally, the Test sub-menu supports the testing of OrderFlow itself, by allowing certain data sets to be loaded, if available on the underlying file system. This feature is only useful in a development environment, i.e. it is not to be used on deployed instances of OrderFlow.