Input Handlers
Input Handlers
The import mapping pre-translation and post-translations are assumed to work on data which is essentially in the OrderFlow native or canonical format. The intention of these translations is to make minor changes as well as to apply business rules to the imported data.
There are situations where additional transformations are necessary just to bring the data into the OrderFlow canonical format.
Example of where this may be necessary include case where data received in non-standard CSV, XLS or JSON formats, or in completely custom formats.
For handling these kinds of situations, OrderFlow supports an array of input handlers. In many cases, there is scripting capability built around these.
CSV and XSLT Input Handlers
| Name | Entities | Usage |
|---|---|---|
| import_asn_delimited | Advanced Shipping Note | Allows for a custom CSV input format for Advanced Shipping Notes. |
| import_delivery_delimited | Delivery | Allows for a custom CSV input format for Deliveries. |
| import_purchaseorder_delimited | Delivery | Allows for a custom CSV input format for Purchase Orders. |
| import_product_delimited | Product | Allows for a custom CSV input format for Products. |
| import_order_delimited | Order | Allows for a custom CSV input format for Orders. |
| import_xslt | Any | Allows for XSLT transformation to be applied to non-standard XML input for Orders. |
Native XML Import Handlers
| Name | Entities | Usage |
|---|---|---|
| import_properties_xml | Any | Allows for data to be imported in the native 'properties XML' format |
| import_structured_xml | Any | Allows for data to be imported in the native full format |
| import_validated_xml | Any | Similar to 'Structured XML' |
Note that for the native XML input handlers, transformations typically aren't necessary, as the data is already in a format that can be read and understood by OrderFlow.
Configuration
The configuration screen for a single input handler is shown below. You can use the 'info' icon on this screen to get more detail on the purpose of the individual fields.
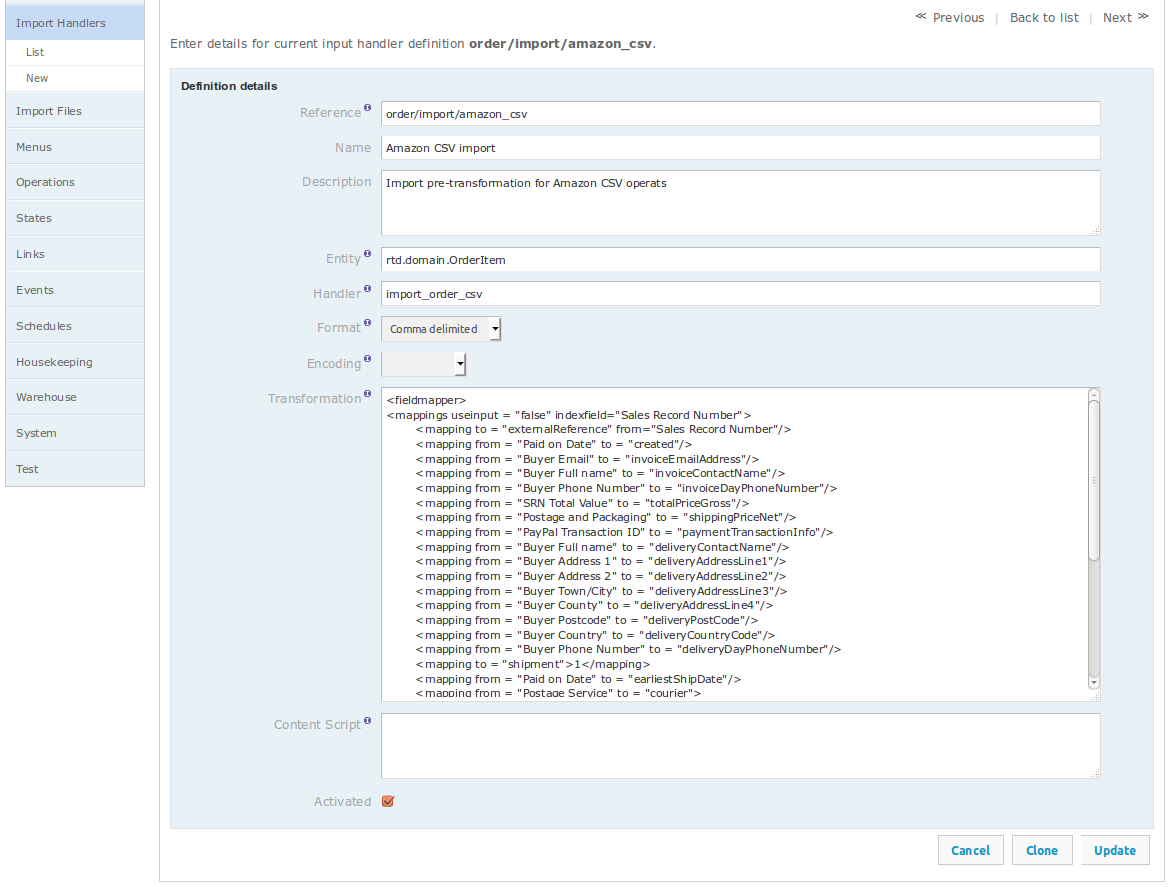
For the purposes of OrderFlow scripting, there are two fields that are important:
- Handler Transformation: an optional handler specific transformation mapping that will be applied to the data in the received custom format.
- Content Script: a script that can be applied directly to the incoming text.
Input Handler Mapping
The two main types of input handler mapping are CSV and XSLT transformations, which are described respectively below.
CSV Input Handler Mapping
CSV-based documents are text documents which have the following tabular structure:
- the first row is the header row which contains the field names for the rows in the document.
- subsequent rows contain the data. Successive values are separated by a delimiter, which is most often a comma, hence the name CSV (Comma-separated values).
- individual data values cannot be multi-line, as it is assumed that each row only uses a single line. There is a way around this, described below.
- if the values themselves contain the delimiter, then the value will need to be enclosed in quotation marks, as in the example shown below.
externalReference,"Description" TEST_123,"A product with a lengthy description, including a comma"
While the comma is the most commonly used delimiter, other delimiters can be used, such as the tab and pipe (|) characters.
The transformation used in a CSV input handler transformation looks very similar to imnport mapping pre-translation, as they both use the fieldmapper XML structure. There are close similarities, but also some notable differences.
An example CSV input handler transformation is shown below:
<fieldmapper> <mappings useinput = "false" indexfield="Sales Record Number"> <mapping to = "externalReference" from="Sales Record Number"/> <mapping from = "Paid on Date" to = "created"/> <mapping from = "Buyer Email" to = "invoiceEmailAddress"/> <mapping from = "Buyer Full name" to = "invoiceContactName"/> <mapping from = "Buyer Phone Number" to = "invoiceDayPhoneNumber"/> <mapping from = "SRN Total Value" to = "totalPriceGross"/> <mapping from = "Postage and Packaging" to = "shippingPriceNet"/> <mapping from = "PayPal Transaction ID" to = "paymentTransactionInfo"/> <mapping from = "Buyer Full name" to = "deliveryContactName"/> <mapping from = "Buyer Address 1" to = "deliveryAddressLine1"/> <mapping from = "Buyer Address 2" to = "deliveryAddressLine2"/> <mapping from = "Buyer Town/City" to = "deliveryAddressLine3"/> <mapping from = "Buyer County" to = "deliveryAddressLine4"/> <mapping from = "Buyer Postcode" to = "deliveryPostCode"/> <mapping from = "Buyer Country" to = "deliveryCountryCode"/> <mapping from = "Buyer Phone Number" to = "deliveryDayPhoneNumber"/> <mapping to = "shipment">1</mapping> <mapping from = "Paid on Date" to = "earliestShipDate"/> <mapping to = "orderLine">input["Sales Record Number_index"]</mapping> <mapping from = "Item Number" to = "product.externalReference"/> <mapping from = "Quantity" to = "quantity"/> <mapping from = "item-price" to = "totalPriceNet"/> <mapping from = "item-tax" to = "totalTax"/> </mappings> </fieldmapper>
The key similarity with import pre-translations is at the level of the individual mapping element. You can use the to and from fields for the source and target field names. The mapping elements can contain scripted or literal values. If you are comfortable with import pre-translations, you are well on your way with input handler transformations.
There are a number of notable differences or new elements.
The useinput attribute
With import pre-translations, it is generally safe to allow useinput to be true, as you can normally assume that the import data file has been constructed with
a reasonable knowledge of the OrderFlow data structure. With input handler transformations, it's normally best to leave useinput to false,
as you would normally want to explicitly map all of the fields from the bespoke format to the OrderFlow format.
No qualifier
There is no qualifier present in the input handler transformation; here, we are working with a single set of data items per row of data.
Field ordering
With import pre-translations, the order of the mapped fields generally does not matter too much, as the ordering is largely determined by the qualifier attribute.
The ordering of the fields in the input handler transformation is very important, especially with order imports.
In the above example, the first set of fields, starting with <mapping to = "externalReference" from="Sales Record Number"/>
are mapped to the top level entity, which in the above example is the order.
The point at which this changes is at the line below:
<mapping to = "shipment">1</mapping>
The value of the to attribute - shipment - here is immediately recognised as the qualifier for shipments. From then onwards, the next set of mappings apply to shipments.
This changes again with the following line:
<mapping to = "orderLine">input["Sales Record Number_index"]</mapping>
Again, the system recognises that the mapping is to the orderLine qualifier, so mappings that follow apply to order lines.
The indexfield attribute
The indexfield attribute is not present in import mapping pre-translations. It is used to identify separate top level entities in imported data.
The the CSV which corresponds with the example input handler translation we displayed earlier.
"Sales Record Number","Buyer Full name","Buyer Phone Number","Buyer Email"..."Item Title","Quantity" TEST_12146571,"DREW MARROW","(01249) 750 564","demo@realtimedespatch.co.uk"...,"FLSH8GB",1 TEST_12146571,"DREW MARROW","(01249) 750 564","demo@realtimedespatch.co.uk"...,"BATT2112",2 TEST_12146581,"DAVIS GORMLEY","(01249) 750 564","demo@realtimedespatch.co.uk"...,"FLSH8GB",1
From inspection, it is fairly clear that the first two data records relate to the same order, while the third relates to a different order. There needs to be a field which is common to all lines in the order, which can identify the order. This field is known as the index field.
In our mapping transformation, the indexfield value is 'Sales Record Number', which also maps to the order externalReference.
<fieldmapper> <mappings useinput = "false" indexfield="Sales Record Number"> <mapping to = "externalReference" from="Sales Record Number"/> ... order fields <mapping to = "shipment">1</mapping> ... shipment fields <mapping to = "orderLine">input["Sales Record Number_index"]</mapping> ... order line fields </mappings> </fieldmapper>
Note also that the field 'Sales Record Number' appears again in the orderLine mapping entry, where it is used to derive a special variable Sales Record Number_index
(note the _index suffix) which can be used to identify the order line number in the order.
One current limitation of CSV order import is that t only supports import of single shipment orders (note how the value for the shipment mapping is set to 1).
However, it does of course support multiline orders and shipments.
XSLT Input Handler Mapping
OrderFlow also support input content transformation for XML documents using XSLT.
For this, the handler needs to be import_xslt.
An example of an order document in a bespoke format is shown below:
<ORDERS> <ORDER> <ORDER_ID>TEST_xslt_1</ORDER_ID> <ORDER_DATE>2014-04-01</ORDER_DATE> <RECIPIENT> <ADDRESS> <ADRESS_LINE_1></ADRESS_LINE_1> <COUNTRY></COUNTRY> <POSTCODE></POSTCODE> </ADDRESS> <NAME>Phil</NAME> <MOBILE>0789 123456</MOBILE> </RECIPIENT> <ORDER_LINE> <ORDER_LINE_ID>1</ORDER_LINE_ID> <SKU>DVD-ABUG</SKU> <QUANTITY>3</QUANTITY> </ORDER_LINE> <ORDER_LINE> <ORDER_LINE_ID>2</ORDER_LINE_ID> <SKU>DVD-MATR</SKU> <QUANTITY>2</QUANTITY> </ORDER_LINE> </ORDER> </ORDERS>
The fields in the example above map easily enough to OrderFlow fields.
An XSLT transformation can be set up to transform the data into the OrderFlow canonical format.
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method="xml" indent="no"/> <xsl:template match="/"> <imports> <xsl:for-each select="ORDERS/ORDER"> <import type="order" operation="insert"> <xsl:attribute name="externalReference"> <xsl:value-of select="ORDER_ID"/> </xsl:attribute> state=created placed=<xsl:value-of select="ORDER_DATE"/> 00:00:00 validated=true currency=GBP channel=magento deliveryAddressLine1=<xsl:value-of select="RECIPIENT/ADDRESS/ADDRESS_LINE_1"/> deliveryAddressLine2=<xsl:value-of select="RECIPIENT/ADDRESS/ADDRESS_LINE_2"/> deliveryAddressLine3=<xsl:value-of select="RECIPIENT/ADDRESS/TOWN"/> deliveryAddressLine4=<xsl:value-of select="RECIPIENT/ADDRESS/COUNTY"/> deliveryCountryCode=<xsl:value-of select="RECIPIENT/ADDRESS/COUNTRY"/> deliveryPostCode=<xsl:value-of select="RECIPIENT/ADDRESS/POSTCODE"/> deliveryContactName=<xsl:value-of select="RECIPIENT/NAME"/> deliveryMobilePhoneNumber=<xsl:value-of select="RECIPIENT/MOBILE"/> invoiceAddressLine1=<xsl:value-of select="RECIPIENT/ADDRESS/ADDRESS_LINE_1"/> invoiceAddressLine2=<xsl:value-of select="RECIPIENT/ADDRESS/ADDRESS_LINE_2"/> invoiceAddressLine3=<xsl:value-of select="RECIPIENT/ADDRESS/TOWN"/> invoiceAddressLine4=<xsl:value-of select="RECIPIENT/ADDRESS/COUNTY"/> invoiceCountryCode=<xsl:value-of select="RECIPIENT/ADDRESS/COUNTRY"/> invoicePostCode=<xsl:value-of select="RECIPIENT/ADDRESS/POSTCODE"/> invoiceContactName=<xsl:value-of select="RECIPIENT/NAME"/> invoiceMobilePhoneNumber=<xsl:value-of select="RECIPIENT/MOBILE"/> shipment.1.priority=0 shipment.1.deliverySuggestionCode=<xsl:value-of select="DELIVERY_SKU"/> shipment.1.deliveryInstruction=<xsl:value-of select="DELIVERY_INSTRUCTIONS"/> shipment.1.orderItem=entity:order <xsl:for-each select="ORDER_LINE"> orderLine.<xsl:value-of select="ORDER_LINE_ID"/>.product.externalReference=<xsl:value-of select="SKU"/> orderLine.<xsl:value-of select="ORDER_LINE_ID"/>.quantity=<xsl:value-of select="QUANTITY"/> orderLine.<xsl:value-of select="ORDER_LINE_ID"/>.state=created orderLine.<xsl:value-of select="ORDER_LINE_ID"/>.unitPriceGross=<xsl:value-of select="UNIT_PRICE"/> orderLine.<xsl:value-of select="ORDER_LINE_ID"/>.shipment=entity:shipment.1 </xsl:for-each> </import> <xsl:text>
</xsl:text> </xsl:for-each> </imports> </xsl:template> </xsl:stylesheet>
Input Handler Content Script
The import handler content can be set to manipulate the text content directly. There are two ways in which this script is typically used:
- to apply generally small modifications to the incoming text itself.
- for complex bespoke incoming data formats.
One example of the former involves interactions with third party systems that send XML data with a byte order mark (BOM) with characters in the UTF-8 encoding.
return rtd.service.infile.transform.InputScriptUtils.maybeStripByteOrderMark(content);
Note the sandboxing rules have been relaxed to allow for some useful functionality to support the string manipulation that is likely to be required when this script is used. Specifically, the following Java packages can be used in scripts:
rtd.service.infile.transformorg.apache.commons.collections
The class rtd.service.infile.transform.InputScriptUtils has some useful static methods which can be accessed in the content translation script:
InputScriptUtils Methods
| Name | Returns Type | Usage |
|---|---|---|
| groupLines(List |
List |
Group lines into several lists, based on the group delimiter. |
| readLines(String input) | List |
Reads the input string into a list of lines. |
| writeLines(Collection |
String | Writes the list of lines into a single string, with each line followed by the ending value. |
| stripFirstLines(List |
List |
Strips the first n lines from the inputted list of lines. |
| stripLastLines(List |
List |
Strips the last n lines from the inputted list of lines. |
| extractQuotedText(String) | String | Extracts string if it is quotation characters, otherwise returns the string as is. |
| maybeStripByteOrderMark(String) | String | Strips the Byte Order Mark (BOM) from a string, if it is present. |
| startsAndEndsWith(String, String) | Boolean | Returns true if the string starts and ends with the specific characters. |
Note that the content script has no knowledge of the OrderFlow domain model, not does it expect the data to be in any particular format when run.
The content script can also be useful if the need arises to translate an input from a highly custom or bespoke format that does not lend itself easily to more familiar translations involving CSV mappings or XSLT.
The content script can also be used to do more basic transformations such as the following:
- strip the first and/or line(s) from the input text
- remove every second line from the input text
Note that the input content script, if present, will be run before the input mapping translation.
Example Usage
Some further examples usages are shown below.
The following example shows how to strip lines from the input text, specifically removing the first two lines.
def lines = rtd.service.infile.transform.InputScriptUtils.readLines(content); def newLines = rtd.service.infile.transform.InputScriptUtils.stripFirstLines(lines, 2); def output = rtd.service.infile.transform.InputScriptUtils.writeLines(newLines, '\n'); return output;
The following example shows how to filter out lines that start with the character '#':
def lines = rtd.service.infile.transform.InputScriptUtils.readLines(content); def newLines = []; for (line in lines) { if (!line.startsWith('#')) { newLines.add(line); } } def output = rtd.service.infile.transform.InputScriptUtils.writeLines(newLines, '\n'); return output;
Scripting Context
The scripting context for the content script includes the following variables:
input
A reference to the input text string.
content
An alias to the same text string.
Return value
The content script needs to return a text string, which is then used as the input text for further operations.
Note that if no transformation is necessary, the script can return a null value, in which case the original input string is used as the input for further operations.