Overview
Overview
OrderFlow is a modular, layered, multi-interface application. It is written mostly in Java, and runs against a MariaDB relational database. It exposes desktop, mobile and handheld user interfaces (via HTTP or HTTPS, accessible from a web browser. It also exposes an XML over HTTP application programming interface (API).
The user interface framework follows the model-view-controller architectural pattern, supported by the Spring application framework, which is modularised using the Impala dynamic modular productivity framework.
OrderFlow is typically deployed within its own standalone Jetty web server, but can also be deployed to run within a separate web server (e.g. Apache Tomcat). It is almost exclusively deployed in Linux-based environments, most commonly using Debian or Ubuntu distributions.
The following diagram shows the technical architecture of OrderFlow at a high level.
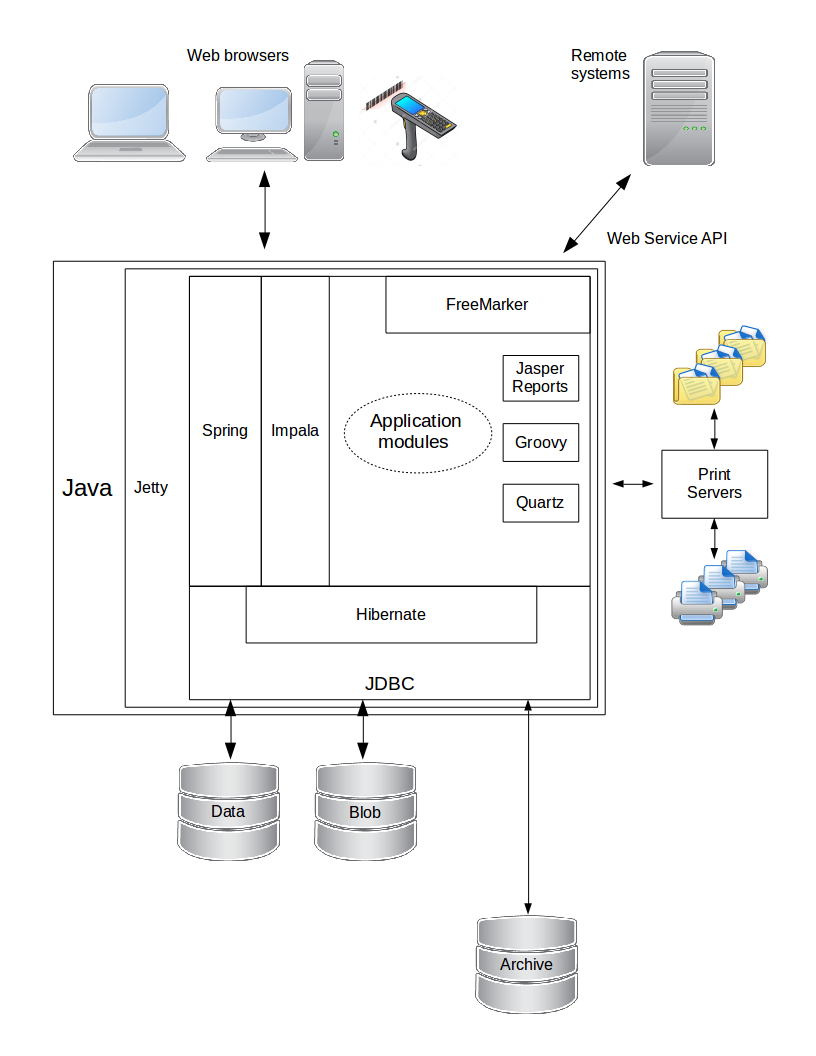
The following notes explain various aspects of this diagram:
- Some of OrderFlow's logic is externalised into scripts written in the Groovy programming language.
- Most of the views (i.e. presentation logic) are written using the Freemarker templating language, to produce HTML, XML, JSON or other data formats.
- Scheduling in OrderFlow is controlled by the Quartz Scheduler Java library.
- OrderFlow facilitates some printing operations via a secondary Print Server Java application, also developed by OrderFlow. This communicates with OrderFlow's internal API to download print jobs and data files to machines local to the warehouse. Print files are then routed to the appropriate network or local printer, data files exchanged with external systems within the warehouse.
- Remote systems that OrderFlow communicates with include shopping cart systems, courier systems, enterprise resource planning (ERP) systems and accounting systems. Such communication can be as a client or server, from OrderFlow's perspective.
- Data extracted from the database can be presented in reports, which can be in textual data formats such as comma-separated values (CSV), spreadsheet format (XLS), or more sophisticated documents using the Jasper Reports Java library.
- Access to the MariaDB database is via Java Database Connectivity (JDBC) and the Object/Relational Mapping framework Hibernate ORM.
- When persisting data, OrderFlow typically separates 'file' data into a separate database, called a Blob (Binary Large Object) database. This is to keep the main (i.e. non-file) database from growing too large. Data from the main database can be archived to another database or the file system, if required.
- OrderFlow can also be configured to run in a clustered configuration for high availability.
The next sections of this document will present different architectural views of OrderFlow.