Home
Introduction
The purpose of this document is to give a more detailed conceptual overview of aspects of OrderFlow.
It is certainly not a complete document, but does contain information useful to administrators who need a more advanced knowledge of certain system features.
If you are new to OrderFlow, we recommend closely reading the OrderFlow Introduction document.
Note
This document is currently in draft and is still a work in progress.
General System Concepts
This section offers some more detail on some of the 'general purpose' entities that have applicability across the whole system. An understanding of what these entites are and how they are used is important, particularly in understanding how multi-channel and multi-site systems are configured.
Modules
OrderFlow uses a modular architecture which allows for bespoke requirements to be introduced in a way which does not impact on or compromise the core system in any way. Modules are loaded when the application is started, and only functionality that is present in loaded modules is available to execute.
The modular architecture allows the system to avoid many of the pitfalls of creating large enterprise systems. It allows the commercial offering to be tailored to the needs of individual customers with the software provisioned without the capabilities that are not needed.
OrderFlow has the concept of core and optional modules. Core modules are included within the base distribution of OrderFlow, so are available automatically to all OrderFlow customers. Optional modules contain more advanced features that are made available according to customer needs and commercial arrangements.
Core Modules
- api: Provides domain model and key interfaces used within application
- courier: Provides basic support for courier integration functionality
- dao: Provides query portion of data access layer of application
- event: Support for event handing within application
- hibernate: Provides object to relation mapping layer of application
- housekeeping: Support for general housekeeping functions, such as log purging
- import: Generic support for import of different types of data onto system
- integration: API integration framework
- main: Provides base implementation
- notification: Support for external communication mechanism (e.g. email, HTTP, FTP, etc.)
- order: Basic order processing support
- paperwork: Support for paperwork generation, including despatch notes
- print: Support for generation of printable items
- process: General purpose process framework, also work with API integration framework
- remote-order: Supports order-related remote API operations
- remote-print: Supports remote API operations relating to printing
- remote-warehouse: Supports warehouse-related remote API operations
- reports-standard: Standard or 'built-in' reports
- schedule: Functionality to support running scheduled jobs
- service: Supports general purpose services within - application (e.g. property lookup, cacheing, etc.)
- user: User management, access and authentication
- view: Provides base support for dashboard-related functionality
- view-admin: Admin-related dashboards
- view-despatch: Despatch-related dashboards
- view-import: Dashboards related to import
- view-integration: Dashboards related to integration with third party systems
- view-reports: Dashboards relating to reporting
- view-setup: Setup-related dashboads
- view-warehouse: Dashboards for warehouse and stock management
- warehouse: Basic warehouse management functionality
- warehouse-stockcheck: Basic stock checking functionality
- web: Base support for user interface
- web-admin: GUI for system administration features
- web-advanced: GUI for advanced setup
- web-despatch: GUI for basic despatch operations (packing, order and shipment searches, etc)
- web-despatch-courier: GUI for courier related despatch functionality
- web-despatch-manifest: GUI for manifest related functionality
- web-despatch-packages: GUI for functionality for creating and managing packages within shipments
- web-import: GUI for data imports
- web-integration: GUI for integration with third party systems
- web-inventory: GUI for basic stock control
- web-reports: GUI for reporting
- web-setup: Setup screens
- web-user: Web layer for providing user access and authentication
- web-warehouse: GUI for basic warehouse management functions
Optional Modules
- accounting-sage: Module to support Sage 200 integration
- activity: Activity logging
- address: Supports basic address validation and cleaning
- archive: Supports controlled archiving and purgeing of operational data
- batch: Batch picking support, sufficient for paper-based batch picking
- batch-taskpick: Further batch picking support, required for handheld picking
- billing: Creation of billing metrics and generation of billing data
- courier-abol: Courier integration with iAbol
- courier-aland: Courier integration with Aland Post
- courier-amazon-mf: Amazon Merchant Fulfilment integration
- courier-bpost: BPost courier integration
- courier-colis: Courier integration with Colis Prive
- courier-correos: Courier integration support for Correos
- courier-dhl: Courier integration with DHL
- courier-dhldeutschepost: DHL DeutschePost integration
- courier-dpd: DPD courier integration (UK)
- courier-dpdnl: DPD courier integration (Netherlands)
- courier-endicia: USPS courier integration using Endicia
- courier-fedex: Courier integration with Fedex
- courier-hermes: Courier integration with Hermes
- courier-huxloe: Courier integration with Huxloe
- courier-hypaship: HypaShip integration
- courier-jerseypost: JerseyPost integration
- courier-landmark: Landmark courier integration
- courier-metapack: Courier integration with MetaPack
- courier-mondial: Courier integration with Mondial Global
- courier-netdespatch: Courier integration with NetDespatch
- courier-parcelperfect: ParcelPerfect courier integration (South Africa)
- courier-postnl: Integration for PostNL
- courier-royalmail: Courier integration with Royal Mail (Tracked)
- courier-royalmailppi: Support for Royal Mail PPI
- courier-springppi: Courier support for Spring PPI
- courier-tnt: Courier integration with TNT
- courier-ukmail: UKMail courier integration
- courier-ups: UPS web services integration
- courier-usps: USPS integration (incomplete)
- courier-whistl: Whistl integration
- courier-wndirect: WnDirect courier integration
- courier-worldship: UPS Worldship integration
- courier-yodel: Yodel DeskDispatch courier integration
- handheld: Handheld terminal application screens
- handheld-support: Support for handheld terminal functionality
- infile: Support for 'fetching' import files
- integration-amazon: Amazon Merchant Web Services integration
- integration-ebay: eBay marketplace integration
- integration-generic: Generic integration support, allowing third parties to build endpoints conforming to OrderFlow API
- integration-magento: Magento integration
- integration-magento2: Magento 2 integration
- integration-shopify: Shopify
- mobile: Mobile application dashboard support
- monitoring: Support for monitoring-related functionality
- multisite: Support for multi-site or -warehouse environemnts
- order-consolidation: Support for despatch using consolidation: including just in time despatch of multiline shipments
- order-expedite: Support manually expediting priority orders
- order-pick: Advanced order picking related functionality
- payment: Support for interactions with payment gateway as part of order processing workflow
- product-group: Basic support for grouped products (bundles, bill of materials)
- productivity: Productivity statistics generation
- remote-monitoring: Remote system monitoring
- reports-periodic: Periodic report generation and export functionality
- scope: Multi-channel and multi-organisation support
- warehouse-advanced: Advanced warehouse management and stock tracking
- warehouse-bom: Bill of materials support
- warehouse-crossdock: Just-in-time despatch of cross docked shipments
- warehouse-licenceplate: Licence plate-related features
- warehouse-po: Purchase order support
- warehouse-stockcheck-advanced: Advanced stock checking through metrics and activity assignment
- warehouse-stockmove: Configurable creation of stock move tasks
- web-despatch-routeplan: Support for grouping and routing despatches
- web-test: Module with features for managing test data sets. Not suitable for use in production environments
The choice of modules that need to be deployed in an environment depend on the feature sets that OrderFlow need to support. The table below provides a list of common features, as well as the modules required to support them.
| Feature | Modules | Also Requires |
|---|---|---|
| Multi-channel or organisation | scope | |
| Multi-site | multisite | |
| Periodic reporting | reports-periodic | |
| Stock move tasks | warehouse-stockmove | |
| Handheld funcntionality | handheld-support, handheld | |
| Single line cross docking | warehouse-crossdock | |
| Multi-line cross docking | warehouse-licenceplate, warehouse-crossdock, order-consolidation | Stock move tasks, Handheld functionality |
| Paper batch picking | batch | |
| Handheld batch picking | batch, batch-taskpick | Handheld functionality |
| Advanced stock checking | warehouse-stockcheck-advanced | Handheld functionality |
| Fetching of import files | infile | |
| Billing | billing | |
| Activity recording | activity | |
| Manual shipment expediting | order-expedite | |
| Bundles | product-group | |
| Kitting/bill of materials | product-group, warehouse-bom | |
| Monitoring | monitoring, remote-monitoring | |
| Data archiving | archive |
Note of course that any courier or eCommerce integration setup will also require the specific modules.
Organisations
The standard OrderFlow environment allows the definition of a single 'default' organisation. The name of the default organisation can be defined as part of the system configuration. All products, inventory, orders and shipments are associated with the default organisation.
- Products are always associated with a single organisation
- Warehouse locations can be associated with a single organisation or can be shared
- Orders and shipments are always associated with a single organisation
- Purchase orders, ASNs and deliveries are always associated with a single organisation
OrderFlow environments that support the optional 3PL (3rd party logistics) module can define multiple organisations to represent the different 3PL clients supported by OrderFlow.
Sales Channels
Incoming orders are generally associated with a specific sales channel. OrderFlow can support different data formats and business logic for each sales channel.
Examples of sales channels might be:
- UK website
- US website
- European Ebay
- European Amazon
The following aspects of an OrderFlow implementation are typically defined differently for each sales channel:
- API integrations with other eCommerce plaforms
- Customer paperwork
- Courier selection logic
- Target and mechanism for stock updates to external systems
In some cases it may be appropriate to parse incoming orders received from a single source and allocate them to different sales channels as a part of the import process. This might be done if an ECommerce shopping cart platform is used to route orders from multiple sources into OrderFlow.
Sites
OrderFlow is a multi-site system. A single instance of OrderFlow will support warehousing and fulfilment operations across multiple sites or warehouses.
Each location defined on the system belongs uniquely to a site.
A site is typically a physical warehouse address but might also be a shop, retail outlet or a distinct logical area within a larger warehouse that needs to be treated as a separate logical entity (e.g. a bonded area within an unbonded warehouse).
OrderFlow environments with the optional multi-site module enabled can support multiple sites.
Sites are one of the primary classifiers for implementing user access permissions across the system. For example, most warehouse operations, such as incoming deliveries, stock moves and stock checks are defined and organised within sites. The major exceptions are cross site stock transfers.
In addition, the fulfilment of shipments is done within a site. Since an order can be broken down into multiple shipments, it is possible for a single order to be fulfilled using different shipments from more than one site.
User access can also be granted at a site level, allowing users on the system to perform operations or view shipments, stock and warehouse information across specific sites but not across the system as a whole. For more details on this, see the Users section of this document.
- Users can be given access to one or more sites
- Locations are always associated with a single site
- Incoming orders do not need to be associated with a site at the time they are received into OrderFlow
- Outgoing shipments are always associated with a single site
Scoping and Configuration
Entity Scope
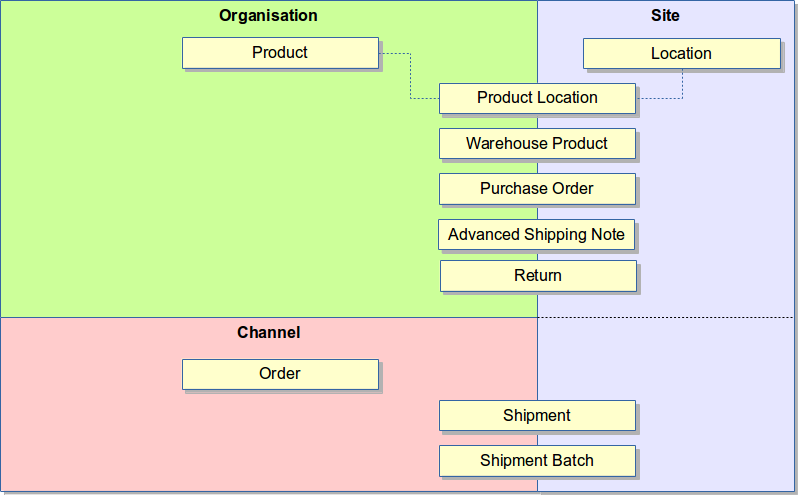
Most of the entities on the system are implicitly scoped, either by site, organisation, or channel, or some combination of these,
- shipments belong to a site. Also, because a shipment comes as part of an order, which belongs to a channel.
- products belong to an organisation.
- locations are part of a site; the stock stock levels associated with a product are site and organisation-scoped.
- deliveries are associated with a site and organisation combination.
This idea is illustrated by the diagram below, showing the scoping of some of the key entities on the system.
Additionally, users are typically scoped in that they will only have access to items belonging to specific sites, organisations and channels on the system.
Entity scoping is a powerful feature that allows for a single instance of OrderFlow to represent a wide range of processes and behaviour ranging across different organisations and channels.
Properties
Any system needs configuration - conceptually, these are the levers used to control how the system behaves in different circumstances. In OrderFlow, configuration is done almost entirely through editable properties which exist on the OrderFlow database. There are hundreds of properties on the system. The properties are organised into groups based on the functional areas for which they are mostly applicable.
Most of the properties in OrderFlow are scoped properties. Scoped properties can take on different values which apply for different sites, channels and organisations, or combinations of the above. This allows for configurability of OrderFlow to match different requirements for different sites and organisational units within the system.
OrderFlow also allows for unscoped or global-only properties, which take only a single value.
Properties are dynamically editable; no system restart is required to reflect changed property values, except in very unusual circumstances.
System states
Sandbox, configuration and live
A new OrderFlow system follows a state transition model to support a controlled transition towards go-live.

When OrderFlow is first deployed it will be given a default state of sandbox which will be displayed in a yellow message bar above the top level menu. The sandbox state has no functional impact on the environment but is used to indicate that it is not being backed up and that any work done in setup and configuration may be lost.
Sandbox environments may be used to test specific problems and are usually temporary.
Before any significant setup and configuration work starts a reliable data backup strategy should be put in place and the system state set to configuration. The configuration state has no functional impact on the environment but is used to indicate that it is being backed up and that the OrderFlow implementation process has started.
Configuration environments are in the process of going live, changes should not be made to the environment without considering the potential business impact.
Before the OrderFlow environment is used to record real stock levels or process live orders the system state should be set to live. The process of setting the system state to live will require that all operational data is deleted.
Any operational data held in the OrderFlow environment when it moved to a 'live' state will be lost, configuration settings will be unchanged.
Organisation and Channel States
OrderFlow environments that support the optional 3PL (3rd party logistics) module can also assign a 'test' or 'live' state to particular organisations or sales channels. This allows 3PLs to define and test new client configurations individually.

While the organisation is in the test state, operational data can be added and cleared as many times as is necessary to verify the configuration.
Other Entities
Some of the entities that play a role in the system are described briefly below.
- workstations: represent the physical workstation from which the user is accessing the system. Useful in particular for configuration of printing behaviour.
- file resources: holds document-based resources such as images, localised message files and product data sheets.
Areas and Locations
Stock in a Warehouse Management System is represented by Products present in Locations. Locations themselves are found in Areas which are in turn contained in Sites. The warehouse as a whole is typically represented as a site, although it is possible to have multple 'logical' sites represented within a single physical warehouse premises.
An example warehouse layout is shown below:
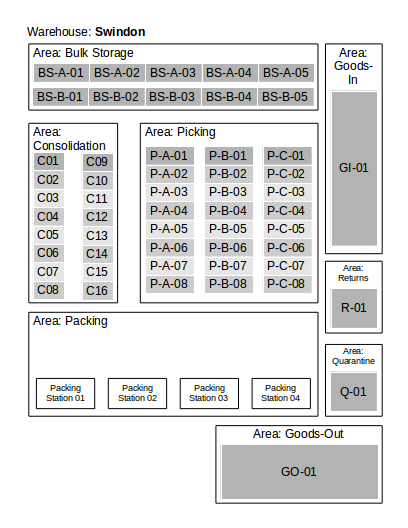
In order to understand how stock management works in OrderFlow, it is important to understand how products and locations can be organised, controlled and configured on the system.
Entities
The diagram below shows the relationships between the entities associated with OrderFlow areas and locations.
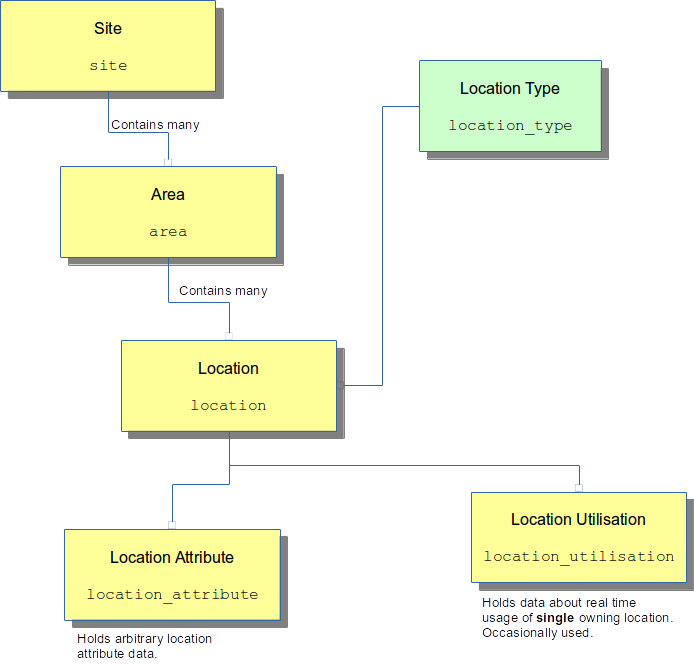
These are discussed in more detail below.
Areas
An OrderFlow Site can be subdivided into different physical areas. Every location on the system is tied to an area entry, which itself is contained within a site.
Areas should represent the physical layout of the warehouse rather than the ways in which different areas of the warehouse are used (e.g. each aisle of pallet racking and each different picking face might be defned as an area).
Areas are primarily a convenience that can be used in the user interface to help users find locations and which allow reports to be run for specific areas within a warehouse.
However, areas can be used to restrict putaway locations for individual products. Areas can also be used to define zones for picking operations, allowing for individual users to be limited to picking within specific areas.
Additionally, areas can play an important role in stock checking functions, as stock check activities are often segmented by area.
The areas are generally a mix of functional and physical.
Functional Areas
Functional areas are areas used predominantly for a specific type of operation, such as in the table below.
| Area | Usage |
|---|---|
| Goods In | An area near the shutter door where deliveries are first held before being processed and putaway. This is often an open floor space but may be marked out into sections |
| Returns | An area dedicated to the processing on returned items |
| Damaged | An area dedicated to holding damaged or stock that is unsaleable for any other reason |
| Consolidation | An area in which locations are temporarily associated with customer orders until all the required items have been brought together and are ready to be packed |
Physical Areas
Physical areas are areas which simply represent the physical space in the warehouse, as in the example below.
| Area | Usage |
|---|---|
| Mezzanine | A mezzanine floor |
| Aisles 001 to 050 | Defining each warehouse aisle as an area |
It is not necessary to define multiple areas within OrderFlow. Each individual location can be defined with specific attributed that will determine how it can be used. As a result it is possible to define 'goods-in' locations, 'freeze' locations and returns locations within a single area which encompasses the whole warehouse.
The only way in which areas are used within the system logic of OrderFlow is to provide default values for all the locations found within the area. If an individual location does not have a logical type it will inherit the logical type defined for the area.
However, in practice warehouse areas are very useful in helping users find their way around the warehouse and in breaking it down into subsections for reporting and for warehouse operations like picking and stock checking.
Locations
Locations are found within areas. Locations themselves are classified by logical location type. It is through the different characteristics of these location types that much of the location-related behaviour on the system is implemented.
Areas can also be used to define zones for picking operations,
Locations are one of the key entities in OrderFlow. All stock on the system is held within locations. Locations are the subject of most of the major warehousing and fulfilment operations from checking in of incoming stock, through to picking of order lines for fulfilment.
Locations included both static locations which occupy a fixed position within the warehouse, and mobile locations, typically used in conjuction with handheld terminals for picking and stock move operations.
OrderFlow stores a range of different data for a location:
- the logical type of the location, described in more detail in the Location Types section.
- the physical type of the location. Example values for this field might be 'bin', 'shelf', 'pallet', 'cart' or 'tote'.
- dimensions of the location, including length, breadth, height, area and volume
- for fixed position locations found within aisles, the elements of the location in terms of aisle number, bay, level can be recorded. In addition, if the position of the location on the left or right hand side of the aisle can be held.
- also for fixed position locations, both a sort indicator and a convenience indicator can be used to influence the system's selection of optimal locations for putaway and picking operations.
Allowing OrderFlow to hold detailed data on the elements of a location's position reduces reliance on location naming conventions to describe the position of locations. However, a suitable naming convention for locations is still recommended as it allow for much easier familiarity with the layout of the warehouse.
Location Utilisation
The location definitions described in the previous section tend to be static in nature; they do not change very often, and tend to change as a result of physical reorganisation rather than warehouse operations.
OrderFlow also allows for the capturing of more dynamic data on the use of location usage through the location utilisation table.
This table allows for data such as the following to be recorded:
- the number of products currently present in the location
- the total volume used, and the percentage utilisation of the location by volume
- a record of when the last stock check was completed
- a mechanism to 'lock' locations to (temporarily) prevent their use in certain processes
Locations are defined to be of specific Location Types.
Location Types
OrderFlow categorises locations into different types, to help it manage the flow of stock more easily. Location Types are configurable entities that can have any combination of various defined attributes. This allows for fine-grained control of how locations are used, particular to the specific customer needs.
There are many attributes of a location type - some commonly-used ones are detailed here:
- pickable: Determines whether this location can be used as a source location for picking operations. If stock is only in non-pickable locations, then replenishment of picking locations must occur before picking can proceed.
- storage: Indicates that the location can be used for storage. Only storage locations will typically be considered as target locations for putaway operations.
- multiProduct: Indicates that a location is designed to contain multiple products.
- incoming: Used specifically for locations for receiving incoming deliveries.
- damaged: Used to hold stock that is considered to be damaged.
- mobile: Used for locations which do not have a fixed physical position in the warehouse. Physically, may be a cart, cage, trolley, tote or some other mobile container. Used extensively in handheld scanner-based operations.
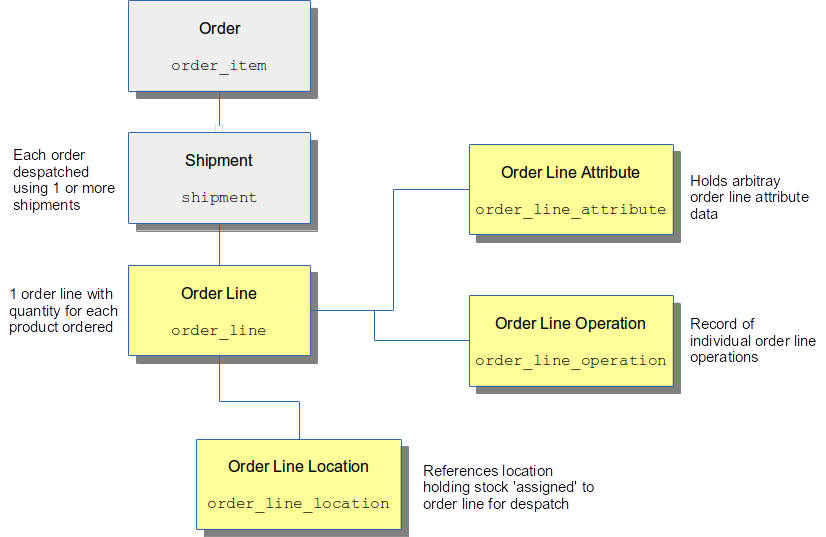
Products
Products are one of the key entities within the OrderFlow database. Products are the items which are received into the warehouse via deliveries, get stored in locations, and get sent out in shipments following the receipt of orders into the warehouse.
Product data includes a range of information, such the SKU, descriptive data, pricing data, an image reference, etc.
In addition to the product data typically received from the shopping cart, an additional set of data may be attached to the data which tends to be specific to warehouse-related operations. This data is stored for each product on a site-specific basis using the warehouse product entity. Data included against this entity includes items such as reorder thresholds, replenishment quantities and primary picking locations. Will be discussed in a bit more detail.
In addition to the warehouse product entity, other entities involved in completing a product definition are listed below.
barcodes: allows multiple barcodes to be stored against a productproduct attributes: allows for arbitrary values to be set up against specific productsgrouped_products: allows for relationships between products, for example for kitted or bundle products
The main entities relating to products are shown in the diagram below.
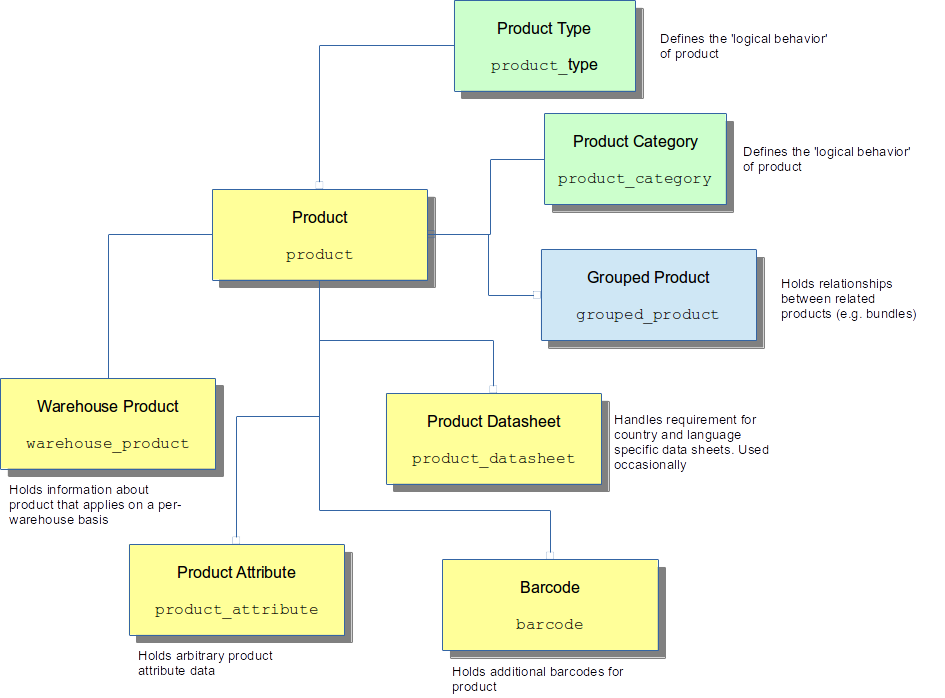
Further detail on these entities and how they are used follows in the rest of this section.
Product Detail
In general, OrderFlow does not perform the function of the master product repository, this function is typically performed by ecommerce front end software (or 'shopping cart'), or a dedicated merchandising system for more complex environments. However, it is possible within OrderFlow to hold quite a rich set of product data, including physical data (weights and dimensions), pricing information, other other descriptive or classifying information such as image references, categories and product types (see next section).
OrderFlow supports the ingestion of product data through a number of ways:
- import via an API integration, typically from a third party system
- import via various file system formats, including CSV, MicroSoft Excel (XLS) and XML
- direct input via the OrderFlow GUI
The fields that can be stored directly against the product are covered in the OrderFlow File Import Specification document.
Barcodes
In a warehousing environment a product is typically identified by a barcode that can be scanned, either by a special handheld device or by a USB scanner attached to a desktop PC.
OrderFlow supports multiple barcode entries per product. This allows for example for a single product to be received from different suppliers with different barcodes without having to relabel any incoming products.
The administrator can choose also choose to set a primary product barcode.
Warehouse Products
OrderFlow makes a clear distinction between product-related information which will typically be managed off the system (for example, within an eCommerce front end or merchandising system), and product-related information which is more closely related to warehouse operations.
For the latter information set, OrderFlow supports warehouse products. Unlike the basic product definition, which applies across all sites or warehouses within the system, the warehouse product data is specific to a particular site.
The warehouse product entry stores information for a number of purposes.
The warehouse product record is also very useful for environments where a distinction is drawn between picking locations and bulk storage locations. OrderFlow supports replenishment tasks which allow for stock to be moved from bulk storage to picking locations. The key data items which drive this process include:
- the replenishment threshold; if stock for a picking location falls below this quantity, the system will trigger a replenishment operation for this product
- the target picking quantity. This influences the number of items that will be moved into picking location(s) as part of the replenishment process
Another feature closely associated with the warehouse product entity is the picking type for a product. A product can be configured to be pickable for products from a single location only. This location is known as the primary picking location. Using a primary picking location has the advantage of making picking operations easy to manage. However, more locations are required for warehouses that use primary location-based picking than for those that use multi-location picking.
For products that use primary picking locations, the relevant location needs to be specified for each product.
The warehouse product entry can also be used to drive reordering processes, through the following values:
- the reorder threshold; when the available stock quantity in the warehouse falls below this value, the reorder process can be triggered
- the reorder quantity, which can be used to govern the reorder increments
Additional data captured against the warehouse product include
- the default (bulk) storage location
- the replenishment threshold and target quantity for this location
Additionally, certain warehouse product entries can be used to restrict the system to suggesting only certain location types or areas for product putaway.
Grouped Products
Grouped product entries are set up on the system to capture relationships between products.
Key examples of these are product bundles and kitted products.
Bundles are products which are composed using a combination of other products. The bundle product is not represented by a single underlying SKU. Instead, it is represented by a number of underlying SKUs.
Bundles are used for example to capture special offers (e.g. buy one, get one free), as well as related combinations of products. For example, a golf set might be sold as a bundle; here the underlying skus would be a driver, a set of two woods, a set of nine irons and a putter.
Kitted products are products which are constructed or assembled using combinations of other underlying products. The underlying products may or may not be sellable but in either case are still held within the warehouse as independent skus for stock management purposes.
In both cases, grouped product are used to capture the relationship between the products. In more general terms, products that are created or derived using combinations of other products are called composite products. For each of these, the grouped product entries list the number of constituent or underlying products.
OrderFlow is able to implement different rules or behaviour for different types of grouped product relationships. For each type of relationship, there is a grouped product definition configuration entry which controls this behaviour.
Product Types
In a manner similar to locations, each product belongs to a product type, which captures essential features of the product. For example, it can be used to determine whether
- the product is a physical entity which needs to stored
- the product is independently sellable
- the product is based on composites of other problems on the system.
The product types themselves are themselves based on a composition of underlying attributes. Key product attributes are listed below.
| Type | Attribute Description |
|---|---|
| Stock | The product has a physical form. It can be stored in a location, and has a measurable quantity. |
| Virtual | The product does not have a physical form, so is not subject to stock management processes. Examples are music downloads, gift experiences, etc. |
| Composite | The product is formed by composing other products. Examples include bundles (composed by defining a single sellable product from multiple underlying products), and manufactured items (created through a manufacturing process). |
| Sellable | The product can be independently sold. |
| Stock Notifiable | Indicates that third party systems may be interested in receiving updates on the stock position of the product. |
The individual product types that are listed on the system are in fact just compositions based on the above types. A couple of examples are listed below.
| Type | Description |
|---|---|
| Default | A sellable stock-based product, eligible for stock notifications |
| Virtual | A virtual product, for which no stock is held, but is sellable. No fulfilment for a product of this type is required. |
| Bundle | A bundle is sellable product which is composed of underlying (typically) stockbased products. It is also a virtual product in the sense that is no physical representation of the bundle sku, only the underlying constituent products. |
- routing of incoming stock into consolidation locations through a JIT (just-in-time) process will use an incoming to consolidation task
- movement of stock from storage to consolidation may involve various tasks, depending on the process used storage to consolidation
Inventory
Stock Control
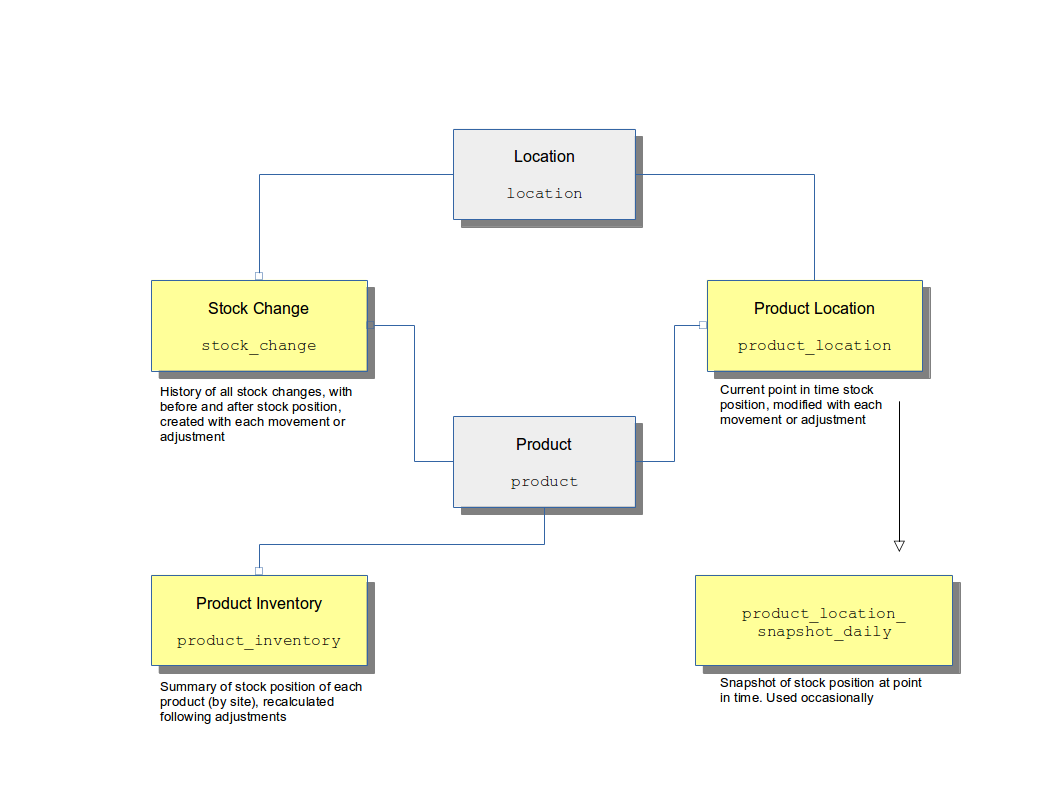
Stock Changes
Inventory Management
Goods-In
The 'Goods-in' operation involves a Delivery of stock into the warehouse.
Deliveries are usually planned and expected. An organisation will place a Purchase Order with a supplier, detailing exactly what items and quantities are required. Supplier purchase orders can be imported into OrderFlow and used to check-in the associated delivery.
If no purchase order has been imported into OrderFlow, it is still possible to describe the contents of a delivery before it is received by using an Advanced Shipping Notification (ASN). An ASN can be used to specify what is thought to be in a delivery before it arrives.
The difference between a purchase order and an advanced shipping note within OrderFlow is that a supplier purchase order can be associated with multiple deliveries while an advanced shipping note is always used to describe a single delivery.
The OrderFlow Goods-In process will reconcile the details of what received with the associated purchase order or ASN and produce a discrepancy report where there are differences between what was expected and what was received.
It is also possible to create a delivery on OrderFlow 'on spec', without it be related to either a purchase order or an advanced shipping note. Where this is done no discrepancy report can be produced.
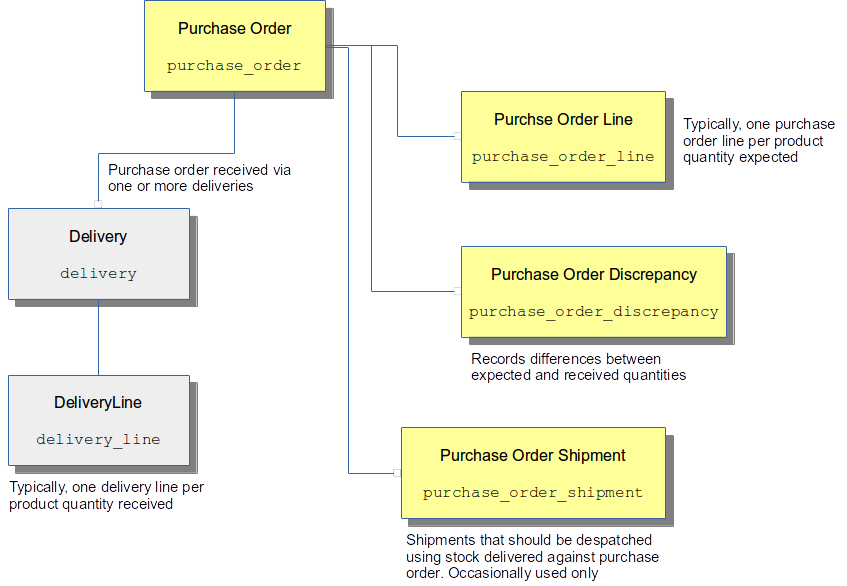
Purchase Orders
A Purchase Order can be of the following types:
- Supplier - placed against one of the organisation's suppliers.
- Bulk Transfer - transfer of stock from another warehouse, within the same organisation.
A Purchase Order Line holds an expected quantity against a referenced product, plus the outstanding quantity of units not yet delivered. It can additionally hold an external reference, typically supplied by an external system.
The following diagram shows the relationship between these entities.
Advanced Shipping Notes
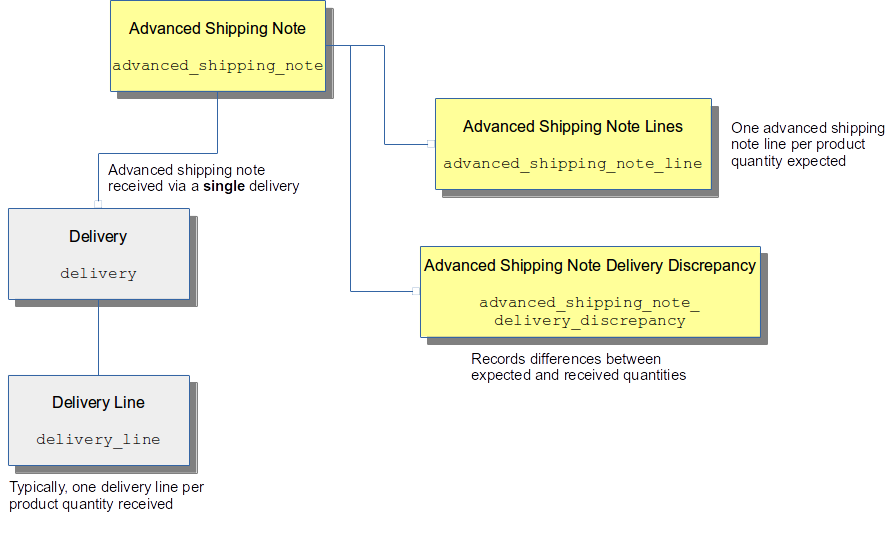
An Advanced Shipping Note can be of the following types:
- Stock - all items in the ASN must be stock items, i.e. when delivered they will be put away into stock locations.
- Container-to-stock - items are delivered against the ASN in containers, whose contents are not confirmed, so will need to be scanned before being put away into stock locations.
- Order - all items in this ASN are intended to be matched with pending orders as part of the Goods-In process, the incoming items will be packed and despatched rather than being put away into stock locations.
- Unrestricted - the delivery for this type of ASN is not restricted to any particular type.
An Advanced Shipping Note Line holds a quantity against a referenced product, and may also hold a (container) location reference or an order reference, depending upon the ASN type.
The following diagram shows the relationship between these entities.
Deliveries
In OrderFlow, a delivery can be one of the following 'standard' types:
- Stock (with deferred save) - the default delivery type, where all products and quantities have to be supplied (to create delivery lines) and the delivery applied before stock is credited to the warehouse.
- Stock (with incremental save) - similar to deferred save, but stock can be credited to the warehouse during the check-in process, instead of waiting until all product/quantity combinations have been supplied.
- Quarantine - similar to deferred save, but stock must be credited to a quarantine location; that is, a location whose logical type has the 'quarantine' flag set. This will credit the stock into the warehouse but will not increase the 'available' stock figure for the items received.
- Container to stock - stock is initially credited as 'unconfirmed', then a verification process must be followed before the delivery can be applied.
- From licence plates - creates one or more temporary licence plate locations that can then be used to route the incoming stock into several different warehouse workflows, typically via the handheld user interface.
Or it can be one of the following 'cross-dock' types. ('Cross-docking' is the process of using delivered stock to fulfil orders directly, without putting that stock away to warehouse storage locations and then subsequently picking it.)
- ASN cross-dock - stock is immediately cross-docked from a delivery that was created from an Order-typed Advanced Shipping Note.
- Purchase Order cross-dock - stock is immediately cross-docked to a shipment that has been associated with the same supplier purchase order that the delivery has been associated with.
- Licence Plate Purchase Order cross-dock - similar to the Purchase Order cross-dock type, but uses a licence plate mechanism to process the stock.
- Out-of-stock cross-dock - incoming stock is immediately cross-docked
with existing customer shipments that have the state 'out of stock'. The
delivery does not need to be backed by an ASN or a purchase order.
Instead, 'out of stock' that are out of stock are automatically matched to use the delivered stock most effectively. Incoming stock that is matched with single line shipments can be packed immediately, incoming stock that is matched with multi-line orders will be moved to a consolidation location.
A Delivery has a lifecycle, defined by the following state transition:
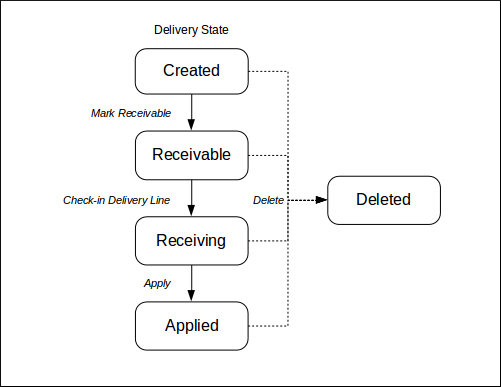
Delivery Line entities will ultimately be created and attached to the Delivery entity, but exactly when these are created depends on the Delivery type (as described above).
A Delivery Line holds the received quantity against a referenced product, and also references the location in which the stock will be credited. Instead of a 'type', a delivery line has a variation, that determines how it will be processed. Delivery Line 'variations' are set by choices made during delivery creation, and can take the following values:
- Just-in-time (JIT) - the delivered units will either be cross-docked, or
routed to a consolidation location, in order to fulfil an order whose stock
has been ordered from a supplier just-in-time (rather than already held in
the warehouse). - Damaged - the delivered units will be routed to a location reserved to hold damaged goods.
- Bulk - the delivered units will be routed to bulk storage locations, using a licence plate mechanism.
- Incoming to stock - the delivered units will be put away to stock, after first being credited to an incoming location; that is, a location whose logical type has the 'incoming' flag set.
- Direct to stock - the delivered units will be put away to stock directly, i.e. without first being credited to any other location.
Stock Moves
Stock Move Tasks
OrderFlow features a generalised framework for managing stock moves within the warehouse. Stock Move Tasks can be set up for a variety of purposes.
An important application of this is in replenishment, described above. OrderFlow uses its task framework to drive the replenishment process.
The task definition that backs this task contains the configuration that dictates how OrderFlow creates the background replenishment task. In this case, the task uses the "Incremental Target-centric" strategy. This uses a "background picking replenishment strategy" report to populate a map of products to quantities of each product that requires replenishment. This map is then used to create the required stock move lines in the task, based on available stock in the warehouse.
Task configuration is a complex area - more details on this subject can be found in the Scripting and Advanced Configuration Guide.
The system entities involved in Stock Move Tasks are shown below.
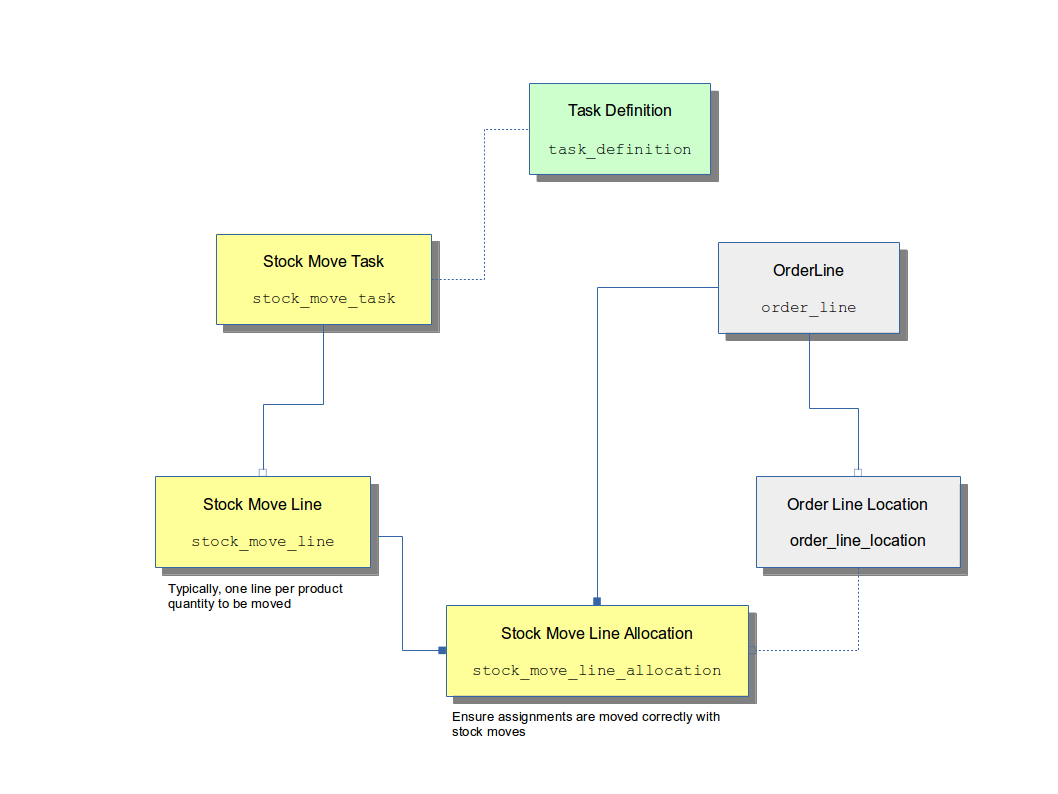
Task Creation
Depending on the particular task, the way it is being used and the process that it is supporting, tasks can either be created on their own or to support a specific process.
For example, an incoming to consolidation task is created to support the movement of a single line of received stock (for just one product) into one or more consolidation locations, each fulfilling the role of temporary holding location for stock required for a single shipment. In this case, the task creation takes place as part of a larger integrated operation which may involve the receipt of a complete delivery.
Similarly, a batch picking task is created to support the picking of a single shipment batch or 'wave'. Here, the task defines the specific lines that need to be picked from storage locations into a mobile target location, such as a tote, cart or trolley.
Tasks that are simply designed to support stock moves from one set of locations to another tend to be created and processed on a standalone basis. Examples of these types of tasks are putaway, replenishment and storage to consolidation tasks.
For tasks that are created on a standalone basis, this creation can either take place manually via the GUI, or automatically via a scheduled job.
Task Completion
Task completion is the process of carrying out the stock moves identified by the task lines. OrderFlow supports two modes of completion for tasks: paper-driven and via a handheld terminal.
The obvious advantages of the desktop-based approach is that it is cheap and simple to implement. However, it does have a couple of disadvantages:
- because none of the items moved are physically scanned during the stock move, it does not a perfect accuracy.
- because all of the stock changes are applied in a single operation on the system after all of the physical moves have been applied for some lines there may be a delay between the time of the physical stock move and the point at which these are reflected on the system.
Standalone tasks are typically completed by selecting a task from the TASK handheld menu. For tasks that are integrated into other workflows, there is normally a transition from one of the other handheld screens into a task picking or putaway sequence.
The processing mode task configuration property determines for each task definition whether handheld or desktop-based processing is supported for that task.
Task States
| Name | Description |
|---|---|
| created | "The task has been created but is not yet ready for processing. This may be because the task lines are still being populated." |
| ready | "The task is ready for processing." |
| applied | "All lines in the task have been completed, and all associated stock moves have been recorded on the system." |
| in progress | "Task processing is under way. The task moves to this state once a handheld user starts working on a task." |
| accepted | "Used to record the fact that the task has been accepted. This is used to take the task off the queue of open tasks with the intention of completion it." |
| printed | "The paperwork for the task has been printed. This needs to take place before the physical stock moves associated with the lines can take place. Once this has taken place, the user can record the stock moves, with an optional step to record modifications prior to committing the stock changes on the system." |
Replenishment
Replenishment is the term used to describe the process of moving stock from storage locations to pickable locations within a warehouse.
Storage locations will typically be locations that are less accessible than pickable locations, for example pallet racking that requires a fork-lift or an aerial work platform (or "man-up") to reach. Retrieving stock from these locations takes more time and can be more difficult. Additionally, specialist qualifications may be required to use the equipment to reach them.
Pickable locations, on the other hand, will typically be more easily accessible to picking staff.
The timing of when to replenish stock is influenced by several factors, including the capacity of the pickable locations, the 'box size' of the stock, the time it takes to access the replenishment locations, and most of all, the outstanding order line requirement.
OrderFlow supports 'priority' replenishment tasks and 'background' replenishment tasks.
Priority Replenishment will move whatever stock is required by existing shipments from bulk storage locations into picking locations. The scope of priority replenishment tasks is restricted to the items needed to by existing shipments with the state 'pending move'. It allows shipments that already exist within OrderFlow to be progressed
Background Replenishment is used to replenish the picking faces by moving stock out of bulk storage locations. An OrderFlow product definition can be given a 'Picking Threshold' value and a 'Picking Location Max' value. When the stock available in the picking face falls below the 'Picking Threshold' the background total quantity available in the pick face up to the value defined in 'Picking Location Max'.
The difference between background and priority replenishment tasks is encapsulated in the report that each task definition uses. The background replenishment uses "background picking replenishment strategy" report, the priority replenishment task uses the "priority location picking replenishment strategy" report.
Orders
A key entity in OrderFlow is the order, which represents a set of items that have been submitted for despatch, typically following the sale of items to end users.
The main relationships on the system for orders are shown below.
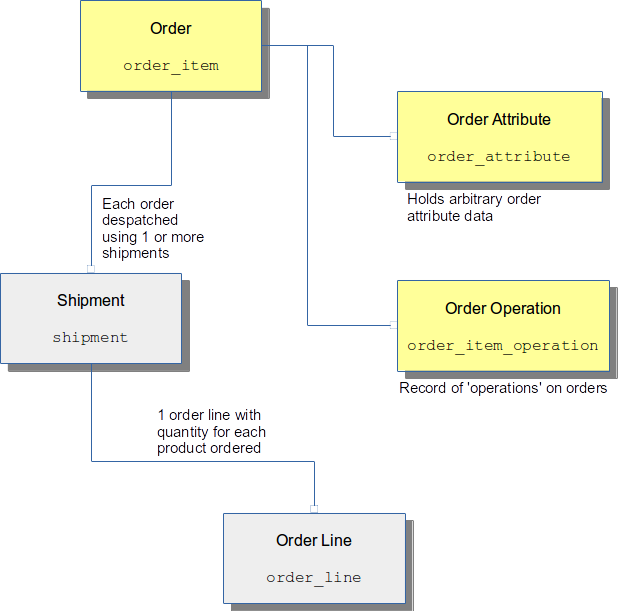
Address and Contact Information
Note where address and contact date can be stored:
- Order delivery address: This will always be populated.
- Order invoice address: The convention is to use the delivery address if this is not set.
- Shipment address: The purpose of this is to override the order delivery address, if necessary, allowing different shipments for the same order to have different addresses).
The following are the address fields used in OrderFlow.
Address Fields
| Field Name | Description |
|---|---|
| line1 | Line 1 of address |
| line2 | Line 2 of address |
| line3 | Line 3 of address |
| line4 | Line 4 of address |
| line5 | Line 5 of address |
| line6 | Line 6 of address |
| postCode | Post code, which will be present for countries and localities that support post codes |
| countryCode | 2 character ISO code for country |
| OrderFlow provides some flexibility over which fields are used for specific purposes, such as city, region, etc., | |
| required in interactions with third party systems. |
This is done through a set of application properties which can be used to refine:
Address Line Properties
| Property Name | Description |
|---|---|
address.building.field |
Used to identify the 'building' element of an address. |
address.city.field |
Used to hold the city or town value for an address. |
address.locality.field |
Used to identify the 'locality' element of an address. |
address.region.field |
Used to hold the state or region value for an address. |
For each set of addresss fields, there is a parallel set of contact fields available, which are described below:
Contact Fields
| Field Name | Description |
|---|---|
| contactName | "The full name of the recipient or invoicee, usually consisting of first and last name in a single field." |
| salutation | The person's title. Only used in some environments. |
| firstName | The person's first name. Only used in some environments. |
| lastName | The person's last name. Only used in some environments. |
| emailAddress | The person's email address. This is almost always provided with incoming order data. |
| dayPhoneNumber | "The best number to reach the person during the day time, either a work or home number." |
| eveningPhoneNumber | "The best number to reach the person in the evening, typically the home number." |
| mobilePhoneNumber | The person's mobile phone number. |
| faxNumber | The person's fax number. Very rarely used these days. |
| companyName | The company name. Applies for orders placed to business addresses. |
Address and contact fields are often used together, for obvious reasons.
Pricing Information
Orders typically are received with prices. This is generally for a number of reasons:
- so that pricing information can be shown on customer paperwork.
- pricing information is also necessary for international shipments for which customs documentation is required.
- to be used in custom reports.
- to be fed through to other back end systems.
It is useful to be aware of the pricing fields available and the convention for their use on OrderFlow.
We start with the elements that make up a 'price' or OrderFlow, then go on to the places where prices are applied.
Price Components
All price values on OrderFlow have the following components:
- Currency: the currency in which the price value is given.
- Gross: the gross price value, after tax.
- Tax: the tax value applied to the price.
- Net: the net price value, before tax.
- Tax Code: optional tax code for the tax value of the price.
When price values are received, some but not all of these values may be provided. OrderFlow is able to calculate implicit values for price elements where necessary. For example, if the gross and tax values are given, OrderFlow can implicitly calculate the net value as the gross less the tax value.
Price Values
The following price values are set up on the system.
Price Values
| Entity | Name | Description |
|---|---|---|
| Order | Total Price | The full price of the order, including goods and shipping. Normally received from the eCommerce system. |
| Order | Goods Price | The price of goods received in the order, but excluding shipping. Can be calculated from the individual line or even product prices. |
| Order | Shipping Price | The price charged for shipping the order to the customer. |
| Order Line | Total Price | The total price for the line. Normally received from the eCommerce system, but can be calculated from the unit price. |
| Order Line | Unit Price | The unit price for the order line. Represents the price applied to a single unit for the line. |
| Product | Price | The sale price for the product. Can be used to derive order line unit price, but may differ from the received value for the order line if a discount has been applied on the eCommerce system. |
Note that where possible we encourage customers to leave price calculations to the eCommerce system, only doing price calculations on OrderFlow when it is absolutely necessary and there is no alternative.
Shipments
The Shipment is one of the key entities in OrderFlow, as it used within the system for managing the despatch of orders. Most of the workflow steps for despatch-related processes revolve around shipments.
The entities associated with shipments are shown below:
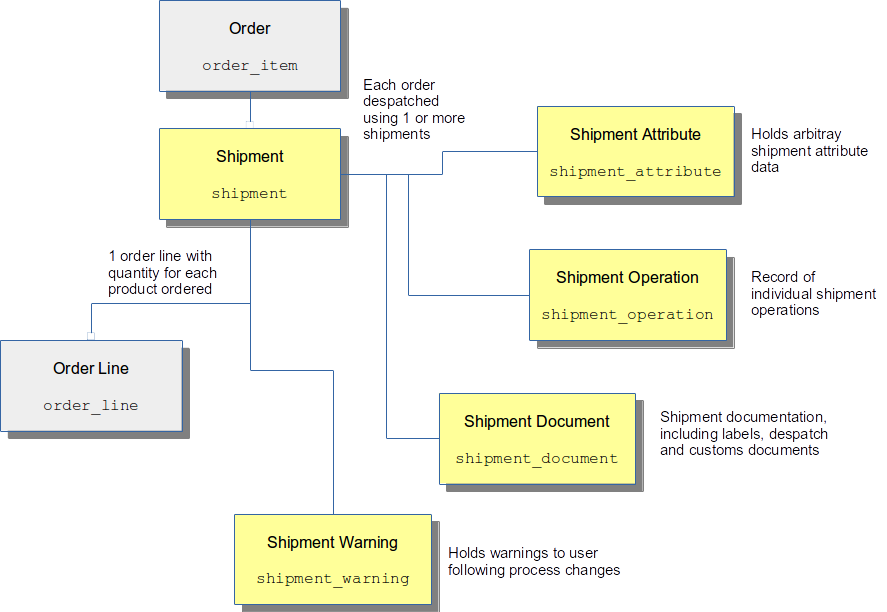
Shipment States
There are several potential states possible for a Shipment as it progresses through OrderFlow, which depend on how the system is configured for a particular client.
One of the most commonly uses set of shipment state transitions is shown below:
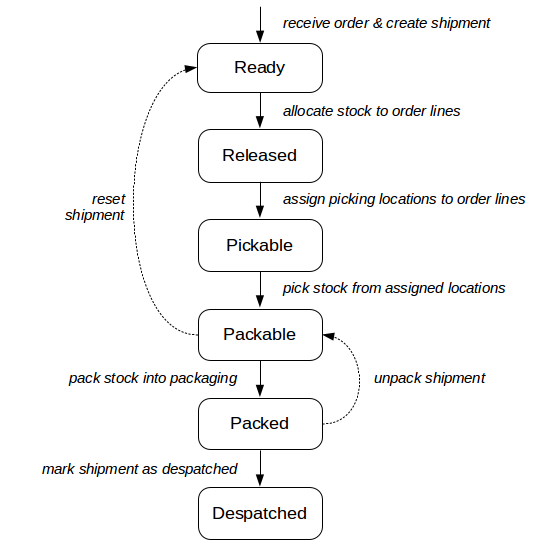
The key states used in the diagram above are:
Key Shipment States
| Name | Description |
|---|---|
| ready | The shipment is ready for processing. This is typically the initial before any processing on the shipment takes place. |
| released | All of the lines of the shipment are in stock. However, the picking locations for these lines still need to be determined. |
| pickable | Picking locations for all lines in the shipment have been determined. The shipment is now ready for picking. |
| packable | If picking is based on paper-based reports rather than handheld terminals, it is not possible to determine exactly when a shipment has been 'picked'. For this reason, the shipment is considered packable as soon as the necessary picking paperwork has been created. |
| packed | Indicates that the shipment has been packed. Packing may involve several sub-processes, from barcode scanning of individual items to be packed, to printing of courier labels and despatch notes. These operations normally occur at a packing desk. In some environments, a slimmed down process that does not involve any packing desk operations can be used. |
| despatched | Typically the last stage in the processing of a shipment. Often involves a notification to a third party system that the despatch of the shipment is complete. |
Other commonly used states include:
- out of stock: one or more of the shipment's lines in out of stock. A line is out of stock if there is insufficient usable stock in the warehouse to meet the line's stock requirement.
- move pending: picking locations cannot be found for one or more lines in the shipment. Typically, a stock move within the warehouse will need to take place before the line can be fulfilled. For example, lines may need to be put away from incoming locations, or picking locations need to be replenished from stock in non-pickable bulk storage locations.
- on_hold: processing of the shipment is temporarily suspended.
- deferred: similar to on hold, but allows for the shipment to automatically become eligible for processing on a particular date, specifically the 'Earliest Ship Date'.
- manifested: a state which may appy in some environments to indicate that a shipment has appeared on a manifest, that is, a record of a group of shipments being despatched together.
Shipment Courier States
In addition to shipment states, a Shipment has shipment courier states, which are discussed in the Courier Management section below.
Allocation and Assignment
Stock Allocation
Stock allocation is the process of identifying whether there is stock present in the warehouse to fulfil the order lines in a shipment. It is performed on a line by line basis. Based on the priority of the outstanding shipments, and other criteria, OrderFlow determines, for each order line, whether there is sufficient stock in the warehouse to meet the order line's stock requirement.
In detail, OrderFlow is typically configured to perform stock allocation automatically on a schedule, although it is also possible to view the current allocation status and to trigger the allocation function from the user interface.
Allocation Process
Invocation of the allocation process results in the following operation sequence:
- For the specified channel, all products in order lines awaiting allocation are extracted from the database.
-
For each product extracted:
- 'Candidate' created or out of stock order lines for the product (that are in ready, out of stock or reset shipments) are extracted from the database, in the order defined by the "Order Line Allocation Sort Expression" application property.
- Additionally, the quantities of stock (for the product) in allocatable locations is extracted. (These locations are ordered according to the "Assignment Location Sort Expression" application property.)
- The 'allocation quantities', i.e. the quantities of all order lines in allocated, move pending, pickable or picked states (for the product) are also extracted.
- If the total of the allocation quantities is equal to (or exceeds) the total quantities in allocatable locations, then all the candidate order lines for the product are marked out of stock immediately, and the allocation process ends for that product. (I.e. there is no spare stock for the product.)
-
If, on the other hand, there is more stock in allocatable locations than the stock already allocated (i.e. there is available stock), then each candidate order line is allocated its required quantity of the product in turn. The order line's state updated to allocated.
- If an order line requires more stock than the remaining amount, then it and all subsequent lines are marked as out of stock. (This is to prevent a situation where a high-quantity line never gets allocated its stock, because it is always given to lower quantity lines.)
-
Finally, the parent shipments of those order lines that have had allocation
attempted will have their state updated, according to the following conditions:- Shipments that have at least one order line out of stock are marked as out of stock.
- Shipments that are either in the ready or out of stock state, but whose order lines have progressed to a state at least as far down the process as the shipment 'allocated' state, will be marked as allocated. (This uses the 'progress indication' mechanism, which is expanded upon in the Progress Indication section below.)
Note that this means that allocation may be attempted for the same product across different channels. However, this does not cause a problem as the process will effectively be skipped for a product that has already undergone the allocation process.
The following diagram depicts an example allocation for product Prod_B:
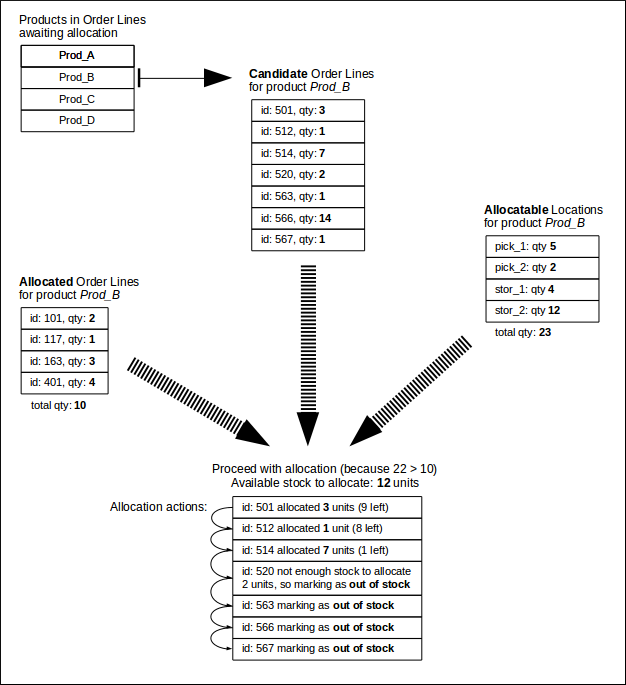
Note that no Order Line Location entries are created during the allocation process.
If there is sufficient stock for a shipment's order lines in the warehouse, then the states of the entities after allocation will typically be as shown below.
Progress Indication
OrderFlow already has a flexible state transition model (for orders, shipments and order lines), using the State Definition and Operation Definition configurable entities. The scriptable nature of the target states in operation definitions allows the transitions between states to be carefully controlled, and to vary based on any aspect of the order / shipment / order lines involved.
However, sometimes workflows can become so complex that maintaining such scripts to define state transitions can become unwieldy. In some cases, certain states in the workflow may need to be skipped, depending upon the shipment context.
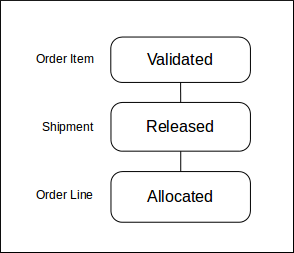
To provide an alternative, each State Definition entity can be assigned a Progress Indication value. This is a number between 0 and 100, which gives an indication of the position of the state in the workflow. The default progress indication values are shown in the following diagram:
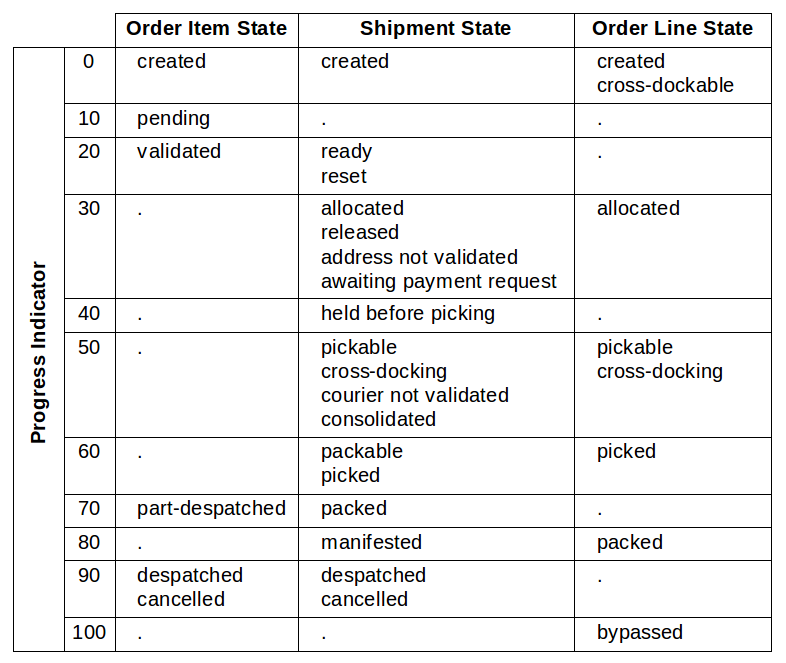
Progress indication values are used during allocation and assignment to determine whether a shipment can be moved to the next state, based on the progress indication of the states of the shipment's order lines. For example, a shipment whose order lines are all in the allocated state can be progressed to the allocated state, as they both have the same progress indication value.
Additionally, if the "Progress Indication State Control" application property is set, the progress indication values are used to determine whether a parent entity's state should be transitioned, based on the progress indication values of all its children, for any state operation.
Stock Assignment
The allocation process assigns the correct states to order lines and shipments depending upon whether the required stock is present in the warehouse.
The stock assignment process goes one step further, and assigns stock from specific locations to allocated order lines. It is possible that an order line could be fulfilled by stock residing in multiple locations, so OrderFlow holds this association in a separate Order Line Location entity.
The assignment process is very similar to the allocation process, but it applies to order lines & shipments in different states, and it creates Order Line Location entities if successful.
- For the specified channel, all products in order lines awaiting assignment are extracted from the database.
-
For each product extracted:
- 'Candidate' allocated or move pending order lines for the product (that are in released or move pending shipments) are extracted from the database, again in the order defined by the "Order Line Allocation Sort Expression" application property.
- Additionally, the quantities of stock (for the product) in pickable locations is extracted. (These locations are ordered according to the "Assignment Location Sort Expression" application property.)
- The 'assigned quantities' i.e. the quantities of all order lines that have an existing Order Line Location record (for the product) are also extracted. (These will be in pickable locations.)
- If the total of the assigned quantities is equal to (or exceeds) the total quantities in pickable locations, then all the candidate order lines for the product are marked as move pending (if they are not already in this state), and the assignment process ends for that product.
-
If, on the other hand, there is more stock in pickable locations than the stock already assigned (i.e. there is available pickable stock), then each candidate order line is assigned its required quantity of the product from one or more of the pickable locations in turn.
The order line's state is updated to pickable.- If an order line requires more stock than the remaining amount available in pickable locations, then it and all subsequent lines are marked as move pending. (This is to prevent a situation where a high-quantity line never gets assigned its stock, because it is always given to lower quantity lines.)
-
Finally, the parent shipments of those order lines that have had allocation
attempted will have their state updated, according to the following conditions:- Shipments that have at least one order line in a 'move pending' state are marked as move pending.
- Shipments that are either in the released or move pending state, but whose order lines have progressed to a state at least as far down the process as the shipment 'pickable' state, will be marked as assigned. This will progress the shipment to its pre-pick state, which is affected by several factors, including its courier state, the result of any configured 'can pick' script, and whether it is a consolidating shipment. If there is no reason not to, the shipment will be progressed to the pickable state.
Note
If the product is configured to have the 'primary only' picking strategy then just the primary picking location is used to assign stock from.
The following diagram depicts an example assignment for product Prod_B. Note that this is not intended to follow on from the allocation example, as in this case there are is additional stock in non-pickable locations, and the 7 candidate lines are all allocated:
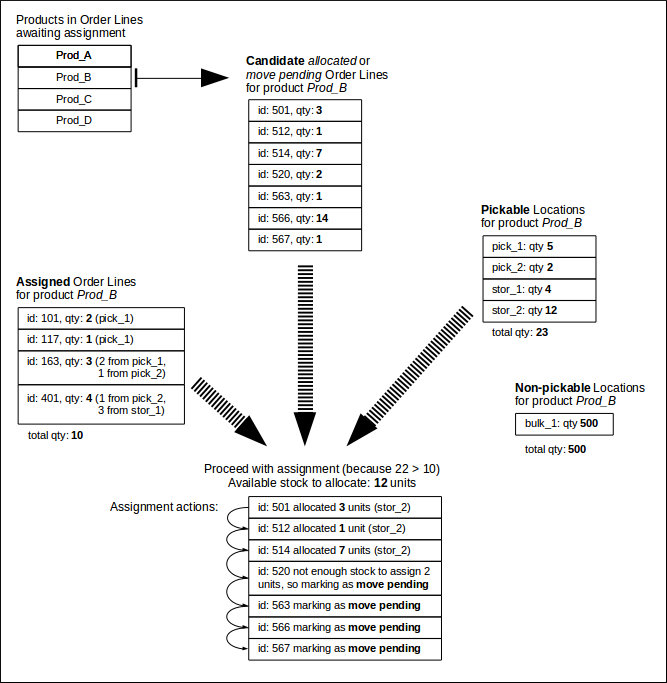
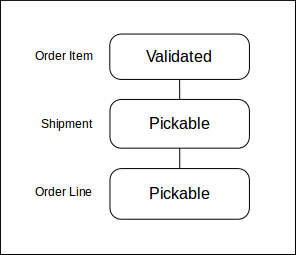
If there is sufficient stock for a shipment's order lines in pickable locations
(and there are no reasons for the shipment to enter another pre-pick state),
then the states of the entities after assignment will typically be as shown
below.
Courier Management
Carriers and Services
OrderFlow integrates with a host of systems to support courier integration. On the system, a courier integration is represented using the courier entity.
In some cases, the integration is directly with the carrier itself. In other cases, the integration is with a third party integration service, such as MetaPack or NetDespatch. When integrating with a third party integration service, this can be done either with a particular carrier and service in mind. However, some integration services, notably MetaPack, will select a carrier and service automatically.
OrderFlow supports a range of couriers to enable shipment of items directly to end user addresses. These courier integrations are both directly through integration with the individual carriers systems, and indirectly through specialist integration services such as MetaPack.
See the Advanced section for more details on Integration.
OrderFlow supports three types of integration with third party couriers. Which of these three types of integrations a particular courier uses does have significant implications for order management workflow as well as on the ground support requirements.
- Web Services API integration. OrderFlow integrates with the courier via a web services API. OrderFlow uses the courier's API to submit details of shipments to be sent out. Usually, the courier returns one or more labels to be printed, either as a PDF document, some image format (such as PNG), or in raw printable text using a printing language such as ZPL. It also normally provides a tracking reference for the customer's use.
The API also often exposes other operations, for cancelling shipments, generating end of day manifests, etc.
Where possible, we favour using a web services API to integrate with couriers in preference to the other methods, described next.
- EDI-based integration. A second type of courier integration involves the use of EDI (Electronic Data Interchange). With this type of integration, OrderFlow manages the assignment of tracking references to shipments internally, typically allocating tracking references from a range provided by the courier. OrderFlow also generates the label internally.
Shipment details are uploaded in bulk to the courier via an end of day manifest, typically either via FTP or HTTP.
This approach has the advantage of allowing the courier integration to easily fit within the order processing workflow. The main weakness is that there is no mechanism for validating the selection of services directly with the courier prior to shipping parcels.
- Desktop software integration. Many courier, particularly those that do not provide a web services API, provide a desktop software application for capturing shipment details and generating labels. These software packages are typically installed on desktop PCs on the packing desk in the warehouse. With the help of the Print Server, OrderFlow normally submits shipment data by writing to a file in a folder monitored by the courier desktop application. It then reads files in that folder to obtain tracking references.
The main advantage of the desktop software integration approach is that less work is required initially for the typical integration. However, these integrations typically require much more support effort to set up and maintain, and are consequently our least favoured type of courier integration.
Third Party Delivery Management
For many of the courier integrations in OrderFlow, the integration is done directly with the carrier's software.
There is an alternative that is becoming increasingly common, where the integration is done not with the carrier directly, but with a third party, known as a Delivery Management System.
The role of the Delivery Management Software falls within a range. The most sophisticated suppliers will:
- provide a unified interface that allows for a common interface, regardless of the choice of carrier.
- performs a service selection, typically based on a cost ranking of available services for the shipment destination, subject to service level requirements.
- prepare labels for the selected service.
- provide additional value-add services, such as delivery tracking, management reporting, etc.
The number of Delivery Management Software providers has grown in recent years, and includes, among others:
OrderFlow Courier Definitions
As a point of terminonlogy, in OrderFlow, a Courier represents an courier integration, not a carrier. The integration may either be direct with one of the carrier's systems, or indirect via a Delivery Management service.
For some carriers, there a several different integration options available. For example, with RoyalMail, integration can be done via:
- NetDespatch, via the courier entries
royalmail_domestic_netdespatchandroyalmail_international_netdespatch - Despatch Manager Online (DMO), via the courier entry
royalmail_dmo - Internally managed in OrderFlow, as in the courier entry
royalmail_tracked
For direct with carrier integrations, there is a direct association between the courier and the carrier, so in this case the carrier and courier terms may be used interchangeably.
For indirect integrations via Delivery Management Software providers, the OrderFlow Courier will typically refer to the Delivery Management system. Depending on circumstances, the carrier may be determined either within OrderFlow, or by the Delivery Management Software.
Courier Management Workflow
In the section below we describe the most common workflow for courier selection and management used in OrderFlow.
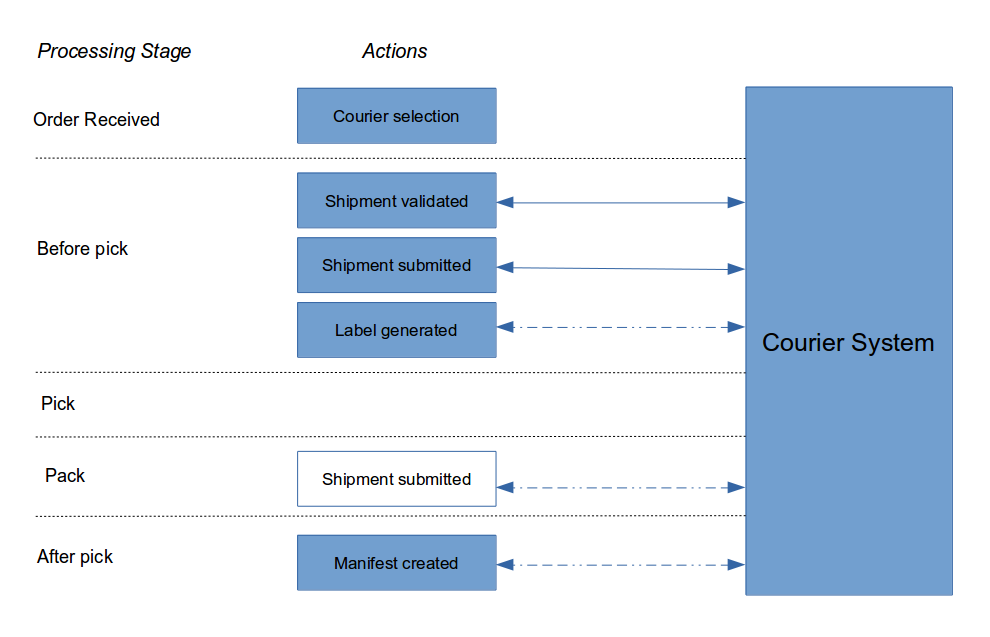
-
Courier selection (described below) is often performed at the time an order and its associated shipment are imported. If a courier selection is required (almost always the case), and no selection is performed on import, then the shipment will typically move into the state
courier_not_selected. -
The shipment is assigned stock and picking locations. Before the shipment moves into the
pickable, the system will determine whether courier validation is required for the shipment. If no validation is required, then the shipment will move directly to thepickablestate at this point. If validation is required, the shipment will move into the statecourier_not_validated. -
If validation is required, the courier validation operation will then be performed, normally automatically via a scheduled job. Courier validation normally involves an operation on the system to determine whether the courier selection is valid for that shipment, and to prepare the label for that shipment. If the validation operation succeeds, the shipment will be moved into the state
pickable, and will be ready for the next stage in the picking workflow. -
If courier validation fails, the shipment will move into the state
courier_invalid. The shipment will need to be modified, or an alternative selection will need to be made manually, in order to allow the shipment to progress. -
Once the shipment has been picked, it will arrive at the packing desk, at which point the label will be printed. Note that if the packer determines that multiple packages are required, then the existing courier submission will be cancelled, and the shipment will be resubmitted for validation with the courier as a multi-package shipment.
Courier Selection
Courier selection typically involves the following:
- selecting the courier (identified by the reference to the OrderFlow courier entry)
- optionally, selecting a service
- optionally, specifiying additional options for the courier or service selection
Courier selection is typically performed using the Courier Selection Script, which is covered in the OrderFlow Scripting Guide document. The courier selection script allows for advanced rules on courier selection to be applied. It is represented by a scoped OrderFlow application property, meaning that different courier selection logic can be applied on a per site, organisation or channel basis, or based on combinations of these.
Note that when using a third party Delivery Management System for integration, the job of the courier selection step may simply be to associate the shipment with that system's OrderFlow courier entry. The actual selection of a carrier may take place only as an outcome of submitting the shipment to the delivery management system. The OrderFlow Scripting Guide also discusses a Delivery Management System specific mechanisms for influencing the carrier and service selection on those systems.
Courier selection is covered in detail in the OrderFlow Scripting Guide document.
Courier Stages
For each courier, an association is made between the Shipment Courier State and the relevant courier stage.
The key courier stages are:
- import: indicates the courier state which the shipment should reach at the point where import is completed. If the import courier state is on or after
partially selected, this may indicate that the courier selection script should be run directly following import. - pick: indicates the courier state which should be reached prior to picking. Mostly commonly used to indicate that courier selection or validation needs to take
place before the shipment can be marked as
pickable. - pack: indicates the courier state the shipment needs to before the shipment can be moved to packing. Typically used to force a courier selection or validation prior to displaying the packing screen.
- label print: typically used to indicate that the shipment needs to be validated or accepted before any attempt can be used to print the shipment label.
- despatch: currently not used. However, may in the future be used to indicate that a shipment needs to appear on a manifest before it can be marked as despatched.
Shipment Courier States
In addition to shipment states, a Shipment has shipment courier states, which relate specifically to the courier selection and label printing processes for that Shipment.
A Shipment can progress (sequentially) through the following shipment courier states:-
Shipment Courier States
| Name | Description |
|---|---|
| not_selected | Used to indicate that no courier selection has been made for the shipment. Typically used to trigger the running of the courier selection script at a point in the shipment processing workflow that is later than import, but still prior to picking. |
| partially_selected | Value for courier against shipment. However, the courier selection is not complete; typically, this means that a courier service or options need to be set. |
| selection_requires_input | Indicates that the courier selection is complete. However, there may be further information required in order for the shipment to progress further through the courier validation and acceptance process. |
| selection_complete | All courier and shipment information is present. However, the shipment may still require external validation, for example, via a Web Services API call. |
| not_validated | Used to indicate that no courier selection has been made for the shipment. Typically used to trigger the running of the courier selection script at a point in the shipment processing workflow that is later than import, but still prior to picking. |
| validated | Applies when a shipment is using a courier for which some additional processing is required prior to picking. This may involve an API call to a third party system. |
| invalid | Indicates that a shipment has failed validation, typically via a call to the courier's web service interface. This may occur if the address data for the shipment is faulty, or if the service selection for the shipment is not valid for the shipping destination. |
| accepted | Indicates that the shipment has been validated and accepted by the courier, for example, through its Web Services API. |
| label_created | Indicates that a courier label has been produced for the shipment. Does not make any statement on whether the label has been printed or not, as this typically takes place at the point at which the shipment is packed. |
| manifested | Indicates that the courier has been accepted into a third party manifest. |
Picking
Picking Mode
The picking mode for a shipment is used to determine the workflow used picking and processing a shipment.
The main picking modes are batch, individual, task, consolidation_single and consolidation_multi.
Batch
This the most common picking mode used. Shipments are picked in groups or batches (also called waves). Before being grouped into a specific batch, the shipment needs to be associated with a batch type, which is typically done at import time with the help of a batch selection script.
Once the shipment has been associated with a batch type and becomes pickable, it is eligible to be included in a specific batch. All of the shipments in that batch are picked together.
Individual
Shipments in this mode are picked individually as soon as they are eligible for picking. As the name suggests, they are picked one at a time, rather than in a group.
Task
Task-based picking involves a three stage process for which the initial picking stage is extremely efficient in terms of metres walked per pick. However it does involve a slightly more complicated process particularly for multi-line shipments:
- picking tasks for shipments are created once the shipment becomes pickable.
- pickers pick shipments efficiently by location across multiple tasks, into pick trolleys.
- the contents of the pick trolleys are emptied into shipment-specific consolidation locations.
- a separate picking process is then followed for picking shipments in consolidation once all of items required for the shipment are present in the consolidation location.
Consolidation single
This type of picking applies specifically for shipments in consolidation. Each shipment is picked to a single consolidation location. This allows for all of the items for the shipment, and only items for that shipment, to be present in the tote presented to the packer.
Consolidation multi
This type of picking applies also for shipments in consolidation, but allows for multiple shipments to be added to the same picking tote. The packer will receive a tote containing items potentially for several shipments.
Batch Picking
A Picking Batch is a grouping of shipments that are picked together. Organising shipments into batches can fulfil a number of purposes.
- related shipments can be grouped together to support a simpler or more efficient operation. For example, single line shipments can be picked more efficiently that multiline shipments, so it makes sense to pick them together. Also, it often makes sense to pick together shipments that share the same priority or courier.
- for paper-based picking processes, a consolidated picking list can be printed for all of the shipments in the batch. It also makes sense in some cases to also pick all of the customer paperwork (despatch notes or invoices) as part of a batch print operation. This can greatly save on time that would otherwise be required for per-shipment print jobs. It also allows for the use of high end printers, as well as for the preparation of paperwork in bulk as part of a background task.
- batches can also be used to support particular workflow processes. The obvious example is picking, either with the help of paper reports or handheld terminals. In some cases, other batch operations can be supported, such as marking all shipments in a batch as packed or despatched.
The diagram below shows a visual example of batch picking. Note that all of the shipments in the batch are picked in full during the batch pick. The ordering of the picking lines is such that the picking is as efficient as it can be subject to this constraint.
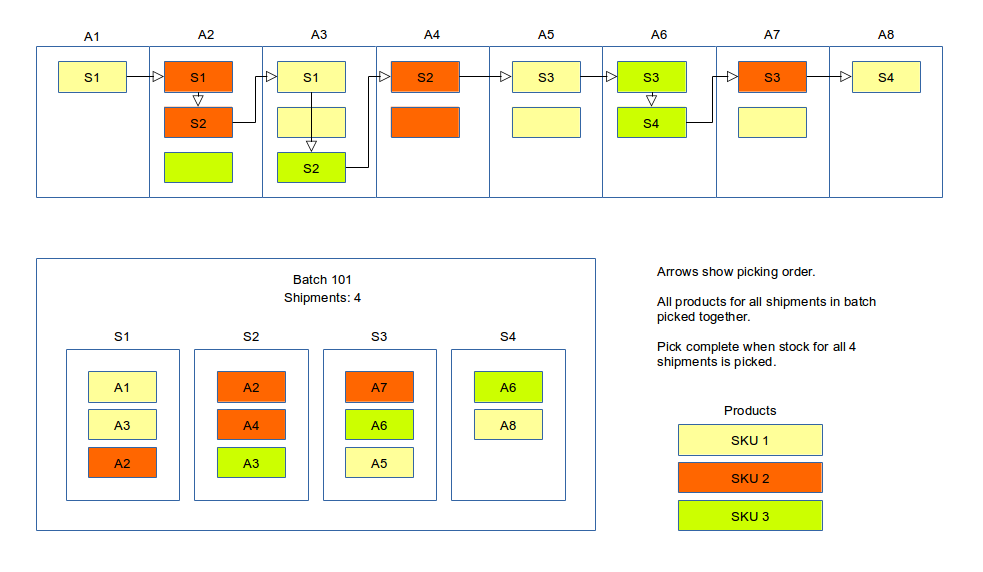
Batching Strategies
Batching allows shipments to be picked depending upon various factors and are usually customer specific.
Some examples are listed below:
- Priority despatch for express orders
- Courier collection times
- Optimising picking based on product location in the warehouse i.e. grouping single-line shipments for products in a defined area. It is more efficient for a picker to go once to an area to pick 12 items than to pick 8 item and return to pick another 4 items.
- Picking shipments in large warehouse i.e. keeping a picker in the same general area.
- If there is a mezzanine, for example, to pick products on the ground floor in one batch and pick products on the mezzanine floor in another batch.
- Split out products that are all barcoded for scan to pack.
- Group special offers (most popular products) into a single batch type.
- Batch shipments for products that require a cherry-picker or fork-lift to allow trained staff to work on those batches.
- Prioritise perishable goods e.g. food
- Bigger batches on a Monday morning to include orders that came in over the weeked.
Note If there are no pickers working in the warehouse e.g. on weekends, then the batch schedule should not be running, but on a Monday morning a customer may want batches with a higher minimum size - rather than chunking up into batches of a smaller size - in order to clear the weekend orders.
Batching Shipments
Three things need to happen in order for shipments to be grouped within a batch:
- the shipment picking mode needs to be set to
batch. Shipments that don't have this picking mode set will not be considered eligible for batch processing. - a shipment needs to be associated with a Batch Type. The Batch Type contains the configuration that will be used to control aspects of batch creation and processing. For example, the Batch Type holds configuration for the minimum and maximum sizes of the batch.
- a batch needs to be created. This will group a number of pickable shipments together. All of the shipments in the created batch will share the batch type associated with with the batch.*
A picker is generally responsible for picking and completing a batch. In paper-based picking the batches are printed off at the print server and assigned to the pickers (usually by a warehouse manager). For handheld scanners, the pickers are presented with the next batch available (or can scroll down to select another one).
Batch Configuration
The most relevant properties to understand the purpose of a batch selection script are:
- Reference - this is the string value that is returned from a batch selection script
- Sort Indicator - an optional integer value to prioritise batches in a handheld pick or the order in which batches are presented in the GUI to print off on the print server. (TBC)
- Min Batch Size - the minimum number of shipments before the batch is created e.g 10 would mean there has to be at least 10 shipments that qualify for a batch (via the batch selection script) before the batch is created for picking.
- Max Batch Size - the maximum number of shipments that can be processed - a limitation might be the capacity of the pickers' cart or tote and the ability of a packer to find the products picke into a mixed, multiline cart.
- Report Picking Sort - the order in which shipments within a single batch are picked e.g. location.sortIndicator (prioritised by picking locations)
- Shipment Sort Expression - the order in which shipments are assigned to a batch e.g. shipment.priority, shipment.earliestShipDate (higher priority shipments oldest shipments are first in the batch to be presented for picking).
Batch Ejection
If a shipment is part of a batch, but for some reason it cannot be processed as part of the batch, then it will need to be ejected, or taken out of the batch.
One cause for ejecting a shipment from a batch is when a short pick occurs. This is when it turns out during picking that some of the stock that has been earmarked for a shipment is either not present or not in a condition suitable for despatch.
One question that arises is what happens to a shipment when it is ejected from a batch. By default, the following will occur:
- if all of the items for the shipment are in the same mobile picking location, then the shipment will be marked as
packable. At this point there is no reason why the shipments cannot be handed to the packer. - if all of the items are in pickable storage locations, then no change is required. Here, it should be possible to introduce the shipment to a new batch without having to reassign picking locations.
- if some of the items have been picked (and are present in mobile locations), while some of the items are still awaiting picking from storage locations, then the shipment will be reset. Effectictively, the shipment will be returned to the start of the workflow.
Note that a shipment can be ejected from a batch manually through user action, and by the system. If a shipment is cancelled, it will automatically be ejected from the batch if it is currently undergoing batch picking.
Handheld Picking
Handheld picking involves the use of handheld terminals (HHTs) to support picking of shipments. Handheld picking is typically used for picking batches, although it is by no means exclusively limited to this. Handheld picking can be used for picking individual shipments, as well as for interleaved task picking, described earlier in this chapter.
Batch Picking Strategies
When doing a batch pick, the picker will pick items from storage into a mobile location (cart, trolley, etc) before handing items to the packer. The trolley can itself be subdivided, allowing for a more fine-grained pick which makes it easier for the packer to find the items that have been picked.
There are three main batch picking strategies that can be used:
| Name | Description | Pros | Cons |
|---|---|---|---|
| Single Mobile Location | All picked items go into a single mobile location | Easy to set up | Harder for packer to find items as they all end up in a single location |
| System-directed Subdivided | The system will associate batch with trolley, but individual shipments will be assigned to sub-locations within the trolley | Very easy for packer as all of the items for shipment are already consolidated | Not as good at handling locations with very different product sizes |
| User-directed Subdivided | The user will scan each item into a subdivision of the trolley, but shipments stock for shipments won't be grouped | Very easy for packer as all of the items for shipment are already consolidated | Packer still needs to do a bit of work to 'group' shipment stock |
In the first iteration of an implementation, using a single mobile location may be the way to go as the setup is easier. If products are small or homogenous, the system-directed subdivided cart offers real efficiency gains. If products vary significantly in size, the user-directed subdivisions provide a balance between efficiency and a solution for the practical diffculties posed by product size differences.
Returns
When the recipient of an order returns a product (or products) for any reason, they usually send those products back to the warehouse from where they were despatched.
Return Entities
The result of an applied return process will be a Return Item entity, attached to which will be one or more Return Line entities. These can be seen under Warehouse --> Returns in the desktop interface.
The following diagram shows the relationship between these entities.
User Permissions
OrderFlow provides a sophisticated access control environment to ensure that the right users get authorised just to the areas on the system for which they require access.
This access control applies both to functional areas on the system (allowing most users only access to a some of the available screens and menus) as well as to data and operations affecting that data.
The main entities associated with user permissions in OrderFlow are shown below.
Note that there is a 'soft' relationship between roles on the one side and menus or operation definitions on the other.
Users
Access to OrderFlow screens is provided only to users properly authenticated by supplying a password.
A user is set up on the system with various items of information, include:
- user name
- password
- email address
- default URI (to which the user navigates by default after logging in)
User access can be optionally restricted to particular sites, channels and/or organisations.
Channel and organisation restrictions are particularly useful for 3PL (Third Party Logistics) environments where the 3PL clients are represented on the system using organisations. An obvious requirement here is that individual customers of the 3PL organisation do not get to see each others' data.
Site access restrictions are useful especially for restricting the access of operational staff to the sites in which they are based.
In addition, a user can be defined as a read-only user. Read-only users have access only to particular screens which have been tagged as read-only enabled.
Roles
At the heart of the access control is are roles, used to identify logical groupings of functionality. Roles are used in conjunction to menus to make screens available to certain users.
Roles can be applied to restrict access in a number of places on the system:
- to menus to ensure that menus and associated URIs are hidden from unauthorised users.
- to order, shipment and order line operations. For example, operations to escalate the priority of particular shipments or to split shipments may be restricted to users with the appropriate roles.
- to dashboard views, controlling the visibility of particular dashboard report fragments.
- to particular reports. For reports which are considered role-restricted, only users with the qualifying role are able to view or run the report.
Menus
Menus have an obvious importance on the system in providing the structure within which areas of the application can be accessed.
Every menu is associated with a URI on the system, so that when users clicks on menu entries, the application navigates to the screen determined using the menu's URI.
For example, the menu Despatch -> Shipments -> Search, itself represented internally by the identifier despatch/shipment/searchnew, is mapped to the URI /despatch/shipment/searchnew.htm.
This screen of course allows you to search shipments.
In addition, every URI is associated with a menu entry. This is important, because role permissions are associated with menus, not URIs directly. (to associate roles with URIs directly would be difficult for a user without detailed knowledge of the application internals).
In other words, it is by assigning permissions to menus that access to particular URIs on the system is given, allowing for fine-grained control of access to functionality on the system.
To understand how this works, let's consider an example. When you select an individual shipment, you are taken to a URI such as /despatch/shipment/detail.htm.
However, as there is no menu entry which points specifically to this URI, the question arises as to how access control can be applied in this case. The answer is that there are a number of mechanisms by which a URI is associated with an individual menu.
The mechanisms for determining the relationship between menu URI are:
URI Menu Resolution
| Name | Usage |
|---|---|
| menu_table | The relationship between the menu and the URI are explicitly declared. |
| annotation | The relationship is inferred from the menu of another URI. |
| convention | The relationship is inferred from the corresponding structure of the menu and the URI. |
More detail on each of these follows.
- menu_table: "This covers the case where there is a direct association between the menu and the URI, as in the case with Despatch -> Shipments -> Search and /despatch/shipment/searchnew.htm."
- annotation: "individual URIs in the code are tagged with an associated
@MenuUriannotation which is used determine the associated menu.
For example, the URIs /despatch/shipment/search.htm and /despatch/shipment/searchreset.htm
both have in the code base @MenuUri annotations pointing to /despatch/shipment/searchnew.htm.
This allows these URIs to 'inherit' the permissions associated with
the /despatch/shipment/searchnew.htm URI.
* convention: if there is neither an entry in the menu table for the current URI, nor
an @MenuUri annotation, the system attempts work out the appropriate menu by convention.
For example, the URI /despatch/shipment/detail.htm is associated with neither
a specific menu table entry, nor does it have a @MenuUril annotation.
In this case, the system attempts to find an appropriate menu by convention.
However, as menus are hierarchical, the matched menu is despatch/shipment; this is the menu with the longest identifier which matches the first part of the URI /despatch/shipment/detail.htm (the leading slash is ignored).